生存分析 ¶
约 4485 个字 3 张图片 预计阅读时间 18 分钟
Acknowledgement¶
本篇在下面这些文章的基础上进行改编,仅用于个人学习,感谢各位作者
什么是生存分析 ¶
情形 1:只记录三年后两组患者的病发情况,检验不同药物对于病发情况是否存在显著差异。 显然,卡方检验即可实现这一研究目标。但该实验本身存在一个巨大缺陷——没有考虑患者的病发时间这一变量。
情形 2:只记录两组患者在三年内的病发时间(此时假设所有患者在观察期内均会病发
情形 3:同时记录两者患者在三年内的病发情况和病发时间(未病发则时间记录为三年
此外,在对患者的随访调查中,很大概率存在失访的现象,在这种情形下,如何正确处理失访数据则显得尤为重要。而生存分析不仅没有将失访数据直接剔除,反而最大程度上利用了失访者的已有随访时间(生存时间
生存函数、风险函数 ¶
令 \(Y\) 表示生存时间这个随机变量,令 \(f_Y(y)\) 表示 \(Y\) 的概率密度函数。
则 \(Y\) 的累积分布函数为:\(F_Y(y) = P(Y \leq y) = \int_0^y f_Y(t)dt\)
由此可见,\(F_Y(y)\) 表示直到时刻 \(y\) 时事件(失效、死亡等)发生的累积概率。
生存函数(survivor function)定义为:\(S_Y(y) = P(Y > y) = 1 - F_Y(y)\),可见,生存函数表示某样本的生存时间大于时刻 \(y\) 的概率。
生存函数可以用来预测生存时间的百分位点,比如:
当 \(S_Y(y) = 0.5\) 时,可以根据这个式子求解中位生存时间 \(y_{0.5}\)。
风险函数(hazard function) 定义为:\(h_Y(y) = \frac{f_Y(y)}{S_Y(y)}\)
可见,风险函数 \(h_Y(y)\) 既不是概率密度,也不是累积概率分布。
不过,我们仍可以把它看做:到时刻 \(y\) 时存活下来的个体在此后一个无限小的时间区间 \([y, y+\partial y]\) 内结局事件(失效、死亡)发生的概率。在这个意义上,风险函数 \(h\) 是risk的一种度量,在时刻 \(y_1\) 和时刻 \(y_2\) 之间,\(h\) 越大,则事件(失效)发生的risk也越大。
为啥可以这么理解风险函数呢?下面给出道理:
由概率密度函数 \(f_Y(y)\) 的定义知:
推导过程:
- 根据风险函数定义式
- 根据概率分布函数定义
- 根据条件概率公式 \(P(B|A)=P(AB)/P(A)\)
至此,就讲明白了上面所说的风险函数 \(h_Y(y)\) 的意义的来源。
国内《医学统计学 · 第四版
已生存到时间 y 的观察对象在 y 时刻的瞬时死亡率。
进一步,基于风险函数 \(h_Y(y)\) 的定义式,我们可以建立风险函数 \(h_Y(y)\) 和生存函数 \(S_Y(y)\) 的关系:
因此,\(S_Y(y) = \exp[-\int_0^y h_Y(t)dt]\),其中,令 \(H_Y(t) = \int_0^y h_Y(t)dt\),称 \(H_Y(t)\) 为累积风险函数。由于 \(h_Y(y)\) 既不是概率密度,也不是累积分布,所以 \(H_Y(t)\) 也不是概率密度或累积概率。不过,它是 risk 的另一种度量指标,其值越大,那么,直到时刻 y 时失效事件的 risk 越大。
指数分布中的风险函数¶
设指数分布的概率密度函数定义为:\(f_Y(y) = \frac{1}{\theta}\exp(-\frac{y}{\theta})\),其中,\(\frac{1}{\theta} = E(y)\)。
于是指数分布的生存函数即为:\(S_Y(y) = 1-F_Y(y) = \exp(-\frac{y}{\theta})\),
进一步得,风险函数:\(h_Y(y) = \frac{f_Y(y)}{S_Y(y)} = \frac{\frac{1}{\theta}\exp(-\frac{y}{\theta})}{\exp(-\frac{y}{\theta})} = \frac{1}{\theta}\),换句话说,
当生存时间服从指数分布时,风险函数 \(h_Y(y)\) 是一个常数 \(\frac{1}{\theta}\),
累积风险函数是:\(H_Y(y) = \frac{y}{\theta}\)。其实,风险函数的不变性是由指数分布的无记忆属性的结果——到时刻 \(t\) 仍存活的个体的余生(还剩下的生存时间)的分布与时刻 t 无关,换句话说,某个体在时间区间 \([t, t+y]\) 内的死亡概率不依赖于起始时间点 t。
Weibull 分布中的风险函数¶
设 Weibull 分布的形状参数为 \(\lambda\),尺度参数为 \(\theta\),
则 weibull 分布的密度函数为:\(f_Y(y) = \frac{\lambda y^{\lambda-1}}{\theta^\lambda}\exp[-(\frac{y}{\theta})^\lambda]\)。
对应的生存函数为:\(S_Y(y) = \int_y^\infty \frac{\lambda t^{\lambda-1}}{\theta^\lambda}\exp[-(\frac{t}{\theta})^\lambda]dt = \exp[-(\frac{y}{\theta})^\lambda]\)。
风险函数是:\(h_Y(y) = \frac{f_Y(y)}{S_Y(y)} = \frac{\frac{\lambda y^{\lambda-1}}{\theta^\lambda}\exp[-(\frac{y}{\theta})^\lambda]}{\exp[-(\frac{y}{\theta})^\lambda]} = (\frac{\lambda}{\theta^\lambda})y^{\lambda-1}\)
求积分,可得累积风险函数 \(H_Y(y) = (\frac{1}{\theta^\lambda})y^\lambda\)
从上面的式子可以看出,Weibull 分布的风险函数 \(h_Y(y)\) 是依赖于时间 \(y\) 的。另外,也可以大略知道,若形状参数 \(\lambda>1\),那么 \(h_Y(y)\) 随着 \(y\) 的增大而增大;若形状参数 \(\lambda<1\),那么 \(h_Y(y)\) 随着 \(y\) 的增大而减小。这样的性质显然比指数分布的恒定风险函数假定来得更加接近实际资料的生存分布。实际上,当 \(\lambda=1\) 时,Weibull 分布就变成了指数分布(原来原来指数分布是 weibull 分布的特殊情形啊
采用 Weibull 分布和指数分布对生存数据建模¶
通常,样本的生存时间会依赖于个体的协变量向量。那么,怎样把协变量对生存时间的影响考虑进去呢?
首先,假定 \(\lambda\) 在个体间是恒定的(每个个体的 \(\lambda\) 都一样
于是,Weibull 分布的风险函数变为 \(h_{Y_i}(y) = (\frac{\lambda}{\theta_i^\lambda})y^{\lambda-1} = (\lambda e^{-\lambda \eta_i})y^{\lambda-1}\)。
如果设 \(x_{i1} \equiv 1\),那么 \(\beta_1\) 就是截距项。进一步设 \(x_{i2}=x_{i3}=\cdots=x_{ip}=0\),意思是说,所有的基线协变量均取值为 0 时,\(h_{Y_i}\) 就是所谓的基线风险函数(baseline hazard function
进一步,可定义风险比(hazard ratio, HR
\(\frac{h_{Y_i}(y)}{h_0(y)} = \frac{(\lambda e^{-\lambda \eta_i})y^{\lambda-1}}{(\lambda e^{-\lambda \beta_1})y^{\lambda-1}} = \frac{e^{-\lambda \eta_i}}{e^{-\lambda \beta_1}} = \exp(-\lambda\sum_{j=2}^p x_{ij}\beta_j)\)
上面这个式子表明,风险比 HR 这个统计量不再依赖于时间 \(y\),于是我们得到了为人熟知的模型——比例风险模型(proportional hazards models
风险函数可写作:\(h_{Y_i}(y) = h_0(y)g(x_i)\),其中,\(g(x_i)\) 是一个非负的函数(毕竟是 exp 函数的值域嘛
PM 曲线 ¶
在临床研究中,常规的生存分析操作主要关注以下三点:
(1)如何计算生存曲线上对应时间点的生存概率?
(2)如何计算中位生存时间?
(3)如何检验不同组生存概率在某因素下是否存在显著差异?
Kaplan-Meier 生存概率估计法 ¶
作为一种非参数估计法,KM 方法本质上是往期生存概率的不断累乘,其核算公式如下: $$ begin{align} S(t_1) &= left(1 - frac{d_1}{r_1}right) \ S(t_2) &= S(t_1)left(1 - frac{d_2}{r_2}right) \ &vdots \ S(t_n) &= S(t_{n-1})left(1 - frac{d_n}{r_n}right) end{align} $$
其中,对于指定时间点 \(t_n\),\(S\) 代表生存概率,\(d\) 代表该时间点事件结局发生数(如患者病发数,死亡数
通过 KM 估计法,我们就可以求得生存曲线上对应时间点的生存概率,关于生存曲线的具体描绘方法,大家感兴趣可以参考画说统计 | 生存分析之 Kaplan-Meier 曲线都告诉我们什么
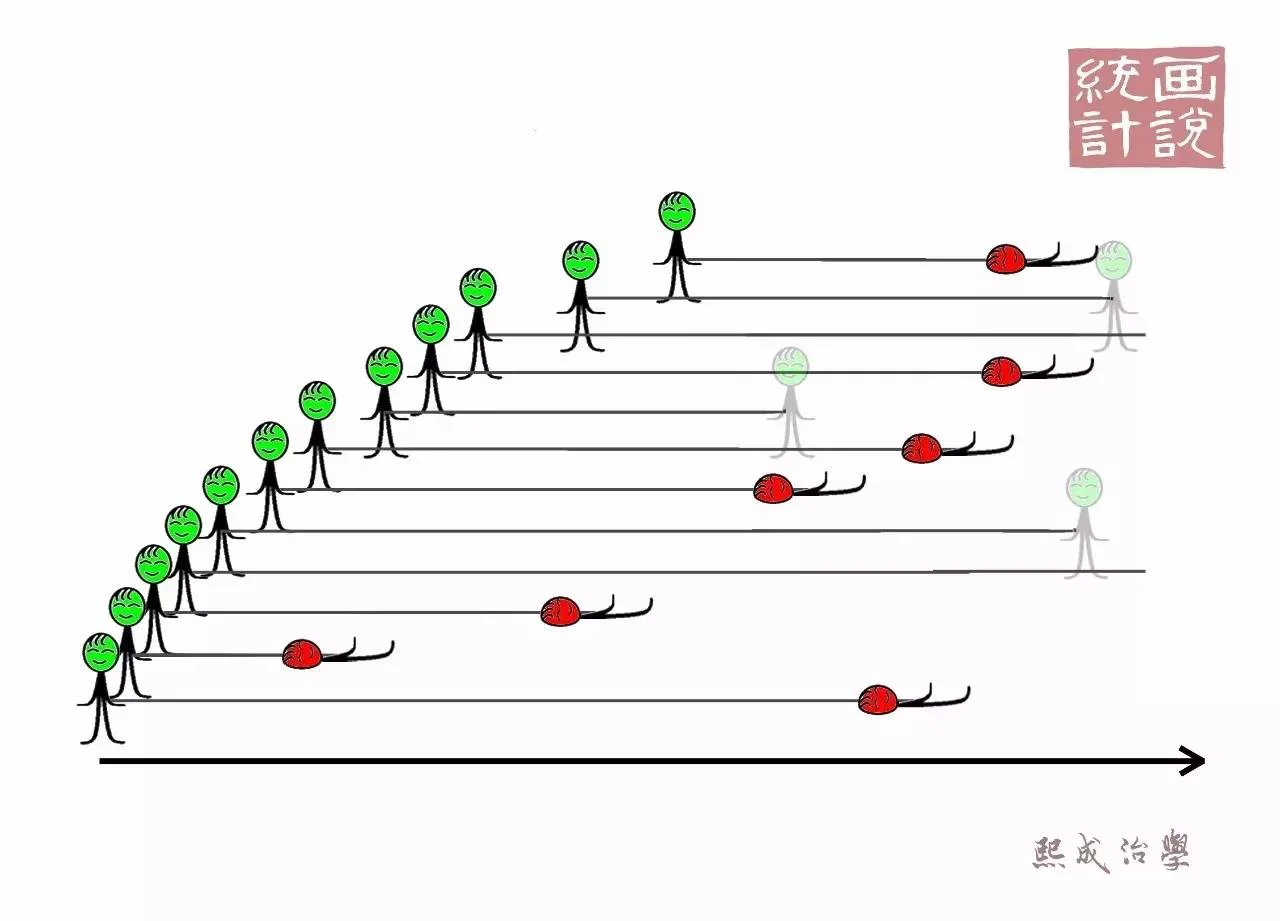
生存曲线呈现折线的样子,每一个“台阶”都对应着一个发生终点事件的时间点
也就是每次有终点事件出现的时刻都会计算一次生存率,把他们用折线连接就构成了生存曲线。
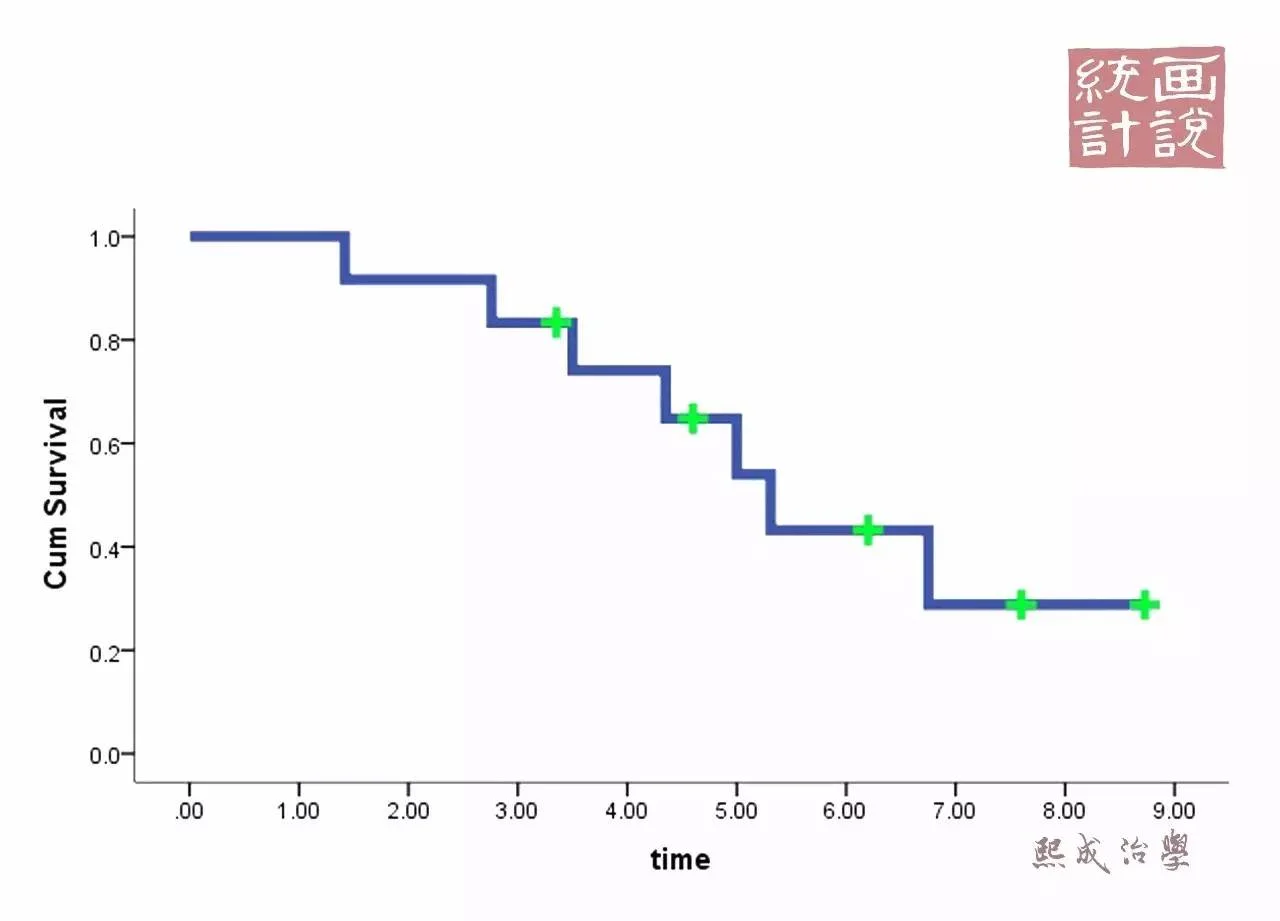
另外,根据 KM 估计法求得生存概率后,我们只需要找到当生存概率为 50% 所对应的时间点,该点值即为中位生存时间。
Log-Rank 检验法 ¶
Log-Rank 检验法在某种程度上类似于卡方检验,关于 Log-Rank 检验的详情大家可参考如下文章:
Log-rank 检验是比较两条生存曲线的常用方法。如果想更深层次的理解这种统计学方法的原理,需要知道 Log-rank 检验的统计量是如何一步步推导出来的。
为了推导 log-rank 统计量,首先介绍两个统计学模型和定理。
(一)超几何分布(Hypergeometric Distribution)
对于一个具有数量为 \(N\) 的有限个元素的总体,总体的元素具有特征 \(A\) 或者 \(B\),具有特征 \(A\) 的元素个数为 \(r\) 个,那么具有特征 \(B\) 的元素个数为 \(N-r\) 个。现从总体中取出 \(n\) 个样本,此 \(n\) 个样本中具有特征 \(A\) 的元素数量记为随机变量 \(Y\),则称随机变量 \(Y\) 服从超几何分布。
使用古典概率模型可得超几何分布的概率分布函数为:
期望和方差分别为:
(二)李雅普诺夫中心极限定理
设随机变量 \(Y_1, Y_2, Y_3,...,Y_n\) 相互独立,并且具有数学期望和方差
若存在正数 \(\delta\) 使得:
则随机变量之和 \(\sum_{k=1}^{n}{Y_k}\) 的标准化变量满足近似的标准正态分布,即
(三)Kaplan-Mier 方法的 K×2×2 列联表
例如,对于 \(k\) 个至事件的时间(例如,OS)\(t_{(1)},t_{(2)},...t_{(k)}\),考虑 \(t_i\):
| 治疗组 | 对照组 | 合计 | |
|---|---|---|---|
| 死亡 | \(d(Ti)\) | \(d(Pi)\) | \(d(i)\) |
| 生存 | \(n(Ti) - d(Ti)\) | \(n(Pi) - d(Pi)\) | \(n(i) - d(i)\) |
| 合计 | \(n(Ti)\) | \(n(Pi)\) | \(n(i)\) |
如果治疗组和对照组的受试者人群与总人群的生存状态是相互独立的,那么在治疗组下死亡的人数 \(D_{Ti}\) 满足超几何分布,其概率分布函数,期望和方差为
根据上述的中心极限定理可得,以下统计量服从标准正态分布,此统计量也称为 Log-rank 统计量。
Case Study:
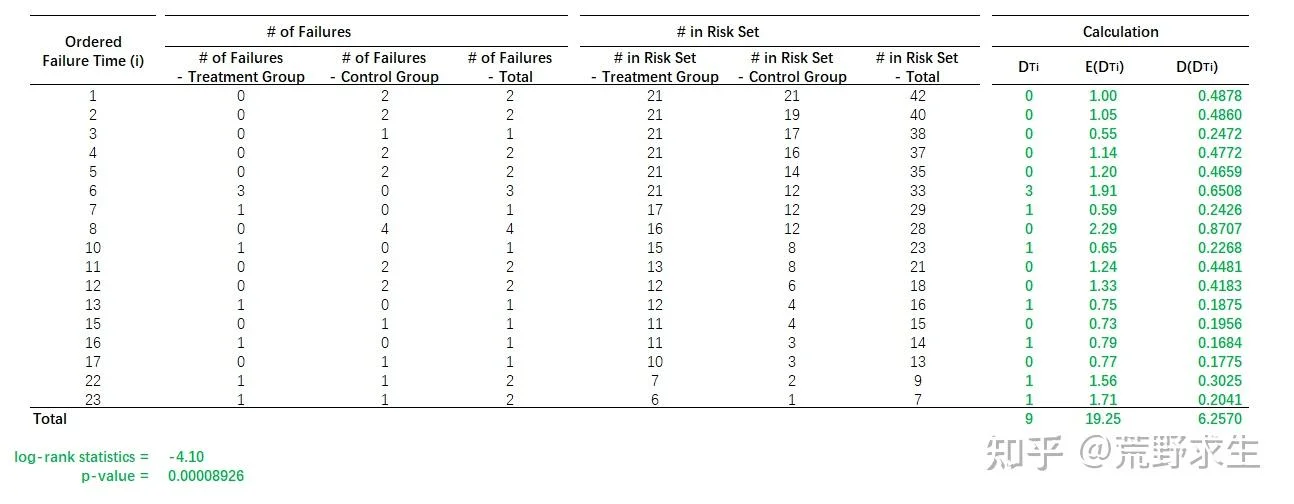
以上 (1) 是一个简单的 log-rank 检验的算例,可见治疗组的生存时间是显著优于对照组的。
Cox 分析 ¶
COX 比例风险模型(cox proportional-hazards model)是英国统计学家 D.R.COX 于 1972 年提出的一种半参数回归模型,它可同时研究多个风险因素和事件结局发生情况、发生时间的关系,从而克服了简单生存分析中单因素限制的不足。
COX 回归分析原理 ¶
作为生存分析的子项目,COX 回归分析的掌握有赖于对生存概率、风险概率、累积风险概率等基础知识的掌握。
在简单生存分析中,由于仅考虑单个影响因素(且为分类型或顺序型变量
而在 COX 回归分析中,需要同时考虑多个影响因素(可为分类 / 顺序型变量,也可为数值型变量
推导 ¶
对于 COX 模型,我们有
其中 \(X=(X_1,\ldots,X_n)'\) 是可能影响生存时间的有关因素,也就是协变量,这些协变量不随时间变化而变化。
方程前半部分 \(h_0(t)\) 是基线风险函数,不需要特定的分布,是非参数模型部分;后半部分是一个参数模型,相当于对多重线性回归的输出进行了次方变换,保证了正值性和单调性。因此我们说这是一个半参数模型。
风险比率(hazard ratio)是两个期望风险的比值:\(\frac{h_0(t)\exp(\beta_1a)}{h_0(t)\exp(\beta_1b)}\)。它并不随着时间变化而变化,因此是随时间成比例的。
有时候我们会将方程写成这样的形式:
\(\beta=(\beta_1,\ldots,\beta_n)\),\(\beta_1\) 表示在给定其他变量不变的前提下,相对于 \(X_1\) 的一个单位的变化带来的风险系数的变化的对数。
案例 ¶
生存分析入门之三(一文读懂 Cox 比例风险回归模型) - 知乎
分析 ¶
如果风险比率接近于 1,那么说明预测因子并不影响生存;如果风险比率小于 1,那么说明预测因子是保护性的(会增加生存几率
COX 模型的主要前提是假定风险比率为固定值,即协变量对生存概率的影响不随着时间变化。只有这一条件得到满足的时候,COX 模型才是有效的。
我们有三种检验方法:
- 分类协变量的每一组 Kaplan-Meier 生存曲线间无交叉;
- 以生存时间 \(t\) 为横轴,对数生存概率 \(\ln[-\ln S(t)]\) 为纵轴,绘制协变量每一组生存曲线,看协变量各组对应曲线是否平行;
- 对于连续型协变量,可将每个协变量与对数生存时间的交互作用项放入模型中,如果交互项统计学上不显著,则满足风险比例条件。
比较 ¶
鉴于临床数据的特殊性,COX 回归比起一般的多重线性回归和 Logistic 回归在临床研究中具有更为广泛的应用。让我们来比较这三种回归分析方法:
-
分析目的:均可用于研究自变量影响程度,校正混杂因素以及作预测分析。
-
自变量类型:均可为连续型数值变量,或离散型分类变量,顺序变量。
-
自变量筛选:均可采用逐步回归方法筛选变量。
-
因变量类型:
- COX 回归:生存资料(包含二分类结局变量和连续型生存时间变量)
- 多重线性回归:数值型变量
- Logistic 回归:分类或顺序型变量
-
因变量数据分布:
- COX 回归:对数据分布不作要求
- 多重线性回归:要求近似正态分布
- Logistic 回归:要求二项分布
-
模型参数解释:
- COX 回归:改变风险比 HR 的自然对数值
- Logistic 回归:改变优势比 OR 的自然对数值
- 多重线性回归:改变 Y 值本身
-
数据删失:
- COX 回归:允许删失值
- 多重线性回归和 Logistic 回归:不允许