数据Data Abstraction ¶
约 3178 个字 293 行代码 1 张图片 预计阅读时间 16 分钟
- sequence
- list
- strings
- tuples
- containers
- sets
- dictionary
序列 Sequence
定义
- 长度
- 元素选择
- 成员判断 (in, not in)
- 切片
| 该程序的一部分 | 把有理数当作 | 仅使用 |
|---|---|---|
| 使用有理数进行计算 | 整个数据值 | add_rational, mul_rational, rationals_are_equal, print_rational |
| 创建有理数或操作有理数 | 分子和分母 | rational, numer, denom |
| 为有理数实现选择器和构造器 | 二元列表 | 列表字面量和元素选择 |
序列遍历
- for 循环
- 解包
- range
序列处理
- 列表推导式
- 聚合(min,max,sum)
- 高阶函数
序列抽象
列表List ¶
列表变量是列表的管理者,不是所有者
初始化 ¶
[],列表字面量用[]表示,里面的元素之间用逗号,分隔
-
一个序列容器乘以一个整数,可以形成一个新的重复若干遍的容器
print('6'*23) print([1,2]*3)
-
“列表字面量”是一个表达式而非常量
a = 2 t = [a, a+1, 3]
-
用切片可以复制和赋值整个列表
name = [1,2,3,4] name[2:] = [5,6,7] # [1, 2, 5, 6, 7] name[2:] = [9,10] # [1, 2, 9, 10]
- 用 del 语句删除元素
输入输出 ¶
用print()直接输出整个列表的时候,也会输出两端的[]
in¬ in判断是否在序列中
print('e' in 'Hello')
print(1 in [1,2,3])
print('el' not in 'Hello')
print([1,2] in [1,2,3])
序列解包 ¶
这种将多个名称绑定到固定长度序列中的多个值的模式称为序列解包(sequence unpacking
函数 ¶
range()用来产生一个数列的迭代器range(b, e, s)不包含右边界
list()可以把这个迭代器转成列表
增
append():在列表后面增加一个元素,返回None
extend():把另一个列表的内容添加到列表的后面
insert():插入
append()和extend()添加一个列表时是不同的
insert()插入到指定位置之前,插入的位置不存在时,加到最后
copy():复制列表
>>> s = [3,4,5]
>>> s.extend([s.append(9), s.append(10)])
>>> s
[3, 4, 5, 9, 10, None, None]
删
remove():删除第一次出现的那个元素,如果没有,则TypeError
del()删除指定位置上的元素
[x:x+1]=[]也可以删除某个位置上的元素
[:]=[]可以清空整个列表
pop():弹出指定位置的元素,不指定则弹出最后一个。返回最后一个值
line = input().split()
while line:
print(line.pop())
查
index():查找第一次出现的位置 列表中不用字符串中的 find 函数 ; 查不到ValueError
reverse():反转自己
sum()
len()
min(),max()
改
c.sort(key = a.index)
列表推导式 ¶
[ expression for item in iterable ]
nl=[number**2 for number in range(1,8) if number % 2 == 1]
#数列求和
n=int(input())
sum([1/i if i%2==1 else -1/i for i in range(1,n+1)])
#求 6+66+666+...+666...666
n=int(input())
sum([int('6'*i) for i in range(1,n+1)])
#双变量 -- 看做 for 的嵌套
[ x*y for x in [1,2,3] for y in [10,20,30] ]
#因数
x = int(input())
[i for i in range(2,x) if x%i==0]
#素数
x = int(input())
not [i for i in range(2,x) if x%i==0]
#zip 与推导式组合用法
a = map(int,input().split())
b = map(int,input().split())
[x*y for (x,y) in zip(a,b)]
字符串String ¶
TypeError: Odd-length string
意思是奇数长度字符串
但我数了好几遍字符串都是偶数的,想不通,我以为我的转化方式有问题,改了好几种转化方式,后来发现在 python 终端直接输入字符串的话可以输出字节数组,就想到可能我之前的文件 file 有问题,果然发现原来在读的时候读进了一个回车,导致字符串成奇数了,所以在读后后可以加一行
f=f.strip('\n')
可以用来取出字符串中的某个字符
s[0]:s 中的第 1 个字符s[x]:s 中的第 x 个字符- 最右边(后)的字符的下标也可以用
-1来表示 - 负的下标从右向左递减,从
-1开始
字面量 ¶
长字符串
- 用 3 个引号(单引号或双引号)括起来的字符串可以包含多行字符串
- 如果要在程序中用多行表示一个字符串,则可以在每行的结尾用反斜杠()结束
- 三个引号的字符串会自动把换行做进字符串数值里,而
\换行的字符串不会
转义字符\
- 如果在字符串的内容中需要出现单引号或双引号,就需要用另一种引号来做前后的括号
| t | n | \ | " | ' | ooo | xyz |
|---|---|---|---|---|---|---|
| 制表位 | 回车换行 | \ | " | ' | 8 进制 | 16 进制 |
print(len(r'hello\nworld'))
#在一个字符串字面量前加一个字符 r,表示这个字符串是原始字符串,其中的\不被当作是转义字符前缀。
字符串计算 ¶
len()返回字符串的长度
-
字符串的
*可以产生重复的长字符串
'*'*10→**********
+可以连接两个字符串
- 字符串中的数据(字符)是 == 不能修改 == 的。
- 去除嵌套
将嵌套列表中的 子元素 合并,可以用
sum函数,第二个参数传入一个空列表[]即可
注意:sum 函数的参数包括两个(iterable 可迭代对象,start 求和的初始值
) ,sum 会把可迭代对象内的元素加在 start 参数传入的初始值上。 因此,如果初始值是个列表,那么可迭代对象也必须要是个列表,且必须是嵌套列表,因为只有这个列表元素也是列表时,这些元素才能跟初始值列表相加。 列表的重复 到 用 sum 展开二层嵌套列表将子元素合并 - 海上流星 - 博客园
sum([[1,2], [3,4]], [])
Out[13]: [1, 2, 3, 4]
切片 slice ¶
s='Zhejiang'
#切片使用负的下标访问
s[1:-3]--> 'heji'
#切片省略第 2 个下标,表示从第 1 个下标开始到最后一个的切片
s[2:] --> 'ejing'
#第 1 个下标为 0 时,可以省略
s[:3] --> 'Zhe'
s[:-2] --> 'Zhejia'
#切片使用第 3 个参数,该参数表示切片选择元素的步长
s[0:5:2] --> 'Zei'
#切片使用第 3 个参数为负数时,表示逆向取切片,逆向时在下标的右边切
s[-1:0:-1] --> 'gnaijeh'
s[::-1] --> 'gnaijehZ'
- 取左不取右;
- 从字符串中取出其中连续的一段的操作叫做切片
- 切片 中的元素编号也可以是负数,来表示从右边开始的编号
- 当切片中的第一个元素编号不存在时,表示从头开始,当第二个编号不存在时,表示到最后一个为止
- 切片还可以有第二个冒号和第三个数据,表示从切片头开始每次加多少
字符串的函数 ¶
-
find()在字符串中查找子字符串所在的位置,如果找不到就返回 -1。当子字符串是单个字符时,就是查找这个字符第一次出现的位置
还有第二和第三个参数,用来表示从哪里开始,到哪里结束
rfind()从后向前寻找
-
count()统计子字符串出现的次数
当子字符串里面只有一个字符时,就是统计字符出现的次数
strip()、rstrip()和lstrip()去掉字符串两端的空格
replace()# 替换子字符串为其他子字符串
upper()、lower()、title()调整大小写
ord()用于获得单个字符的 Unicode 编码
-
chr()用于获得某个编码所代表的字符chr(ord('A')+1)
-
字符串
join:用字符串做分隔符将列表中的元素组成一个字符串a = ['hello','good','boy','wii'] print(' '.join(a)) print(':'.join(a))
membership¶
具体来说,成员运算符 in 应用于字符串时的行为与应用于序列时完全不同,它匹配的是子字符串而不是元素
iterate 遍历字符串 ¶
s = input()
##下标写法
while i < len(s):
print(s[i])
i+=1
##for in 写法
for i in s:
print(i)
##enumerate() 写法
for i, element in enumerate(seq):
print(i, element)
##内置函数 iter()
for every_char in iter(girl_str):
print(every_char)
enumerate()函数用于将一个可遍历的数据对象 ( 如列表、元组或字符串 ) 组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中
- 逆序的写法
## 字符串切片
a[::-1]
## reversed 函数
print(''.join(reversed(a)))
## 利用列表
-
修改字符串的方法
##转换成列表,修改后用 join 变成新字符串 s1 = list(s) s1[4] = 'E' s = ''.join(s1) ## 序列切片方式 s='Hello World' s=s[:3] + s[8:] ## 使用字符串的 replace 函数 s = 'Abcdef' s=s.replace('bcd','123')
Split¶
a, b = map(int, input().split('/'))
split()根据所给的参数字符串,将字符串分隔为一些字符串,放在一个列表里
'12/18'.split('/')` --> `['12', '18']
元组Tuple ¶
- 与列表相似,元组
Tuple也是个有序序列,用()生成。而且元组的字面量也实际上是表达式 - 可以被索引、切片
- 不能修改,所以是静态的,在大数据样本上处理速度较快
(2)不能被当作是元组
Tuple 函数 ¶
tuple()将列表转成元组
集合Set ¶
(set)是⼀类容器- 没有先后顺序不重复
- 集合的字面量用花括号 {}
Set 初始化 ¶
- 直接给变量赋值⼀个集合字面量
- 使⽤
set()创建⼀个空集合 - 使⽤ set() 将列表或元组转换成集合
- 集合的值不重复,创建集合的时候,python 会消除重复的值。
- 集合的元素是不可变对象
- 但是集合本身是可变的
- 集合内的元素是⽆序的,所以不能通过下标来访问集合元素
Set 函数讲解 ¶
| 函数 | 示例 | 结果 | 说明 |
|---|---|---|---|
| len() | len(s) | 5 | 返回集合中元素的数量 |
| min() | min(s) | 2 | 返回集合中最⼩的元素 |
| max() | max(s) | 11 | 返回集合中最⼤的元素 |
| sum() | sum(s) | 27 | 将集合中所有的元素累加起来 |
| add() | s.add(13) | {2,3,5,7,11,13} | 将⼀个元素加⼊集合中 |
| remove() | s.remove(3) | {2,5,7,11} | 从集合中删除⼀个元素,如果这个元素在集合中不存在,则抛出 KeyError 异常 |
| sorted() | 排序,返回列表 | ||
| update() |
运算 ¶
| 运算 | 函数 | 运算符 | 示例 | 结果 | 说明 |
|---|---|---|---|---|---|
| 并集 | union() |
| | s1.union(s2) |
{2,3,4,5,6,7,11} |
结果是包含两个集合中所有元素的新集合 |
| 交集 | intersection() |
& |
s1 & s2 |
{2,3,5,7} |
交集是只包含两个集合中都有的元素的新集合 |
| 差集 | difference() |
- |
s1 - s2 |
{11} |
s1-s2 的结果是出现在 s1 但不出现在 s2 的元素的新集合 |
| 对称差 | symmertric_difference() |
^ |
s1 ^ s2 |
{4,6,11} |
结果是⼀个除了共同元素之外的所有元素 |
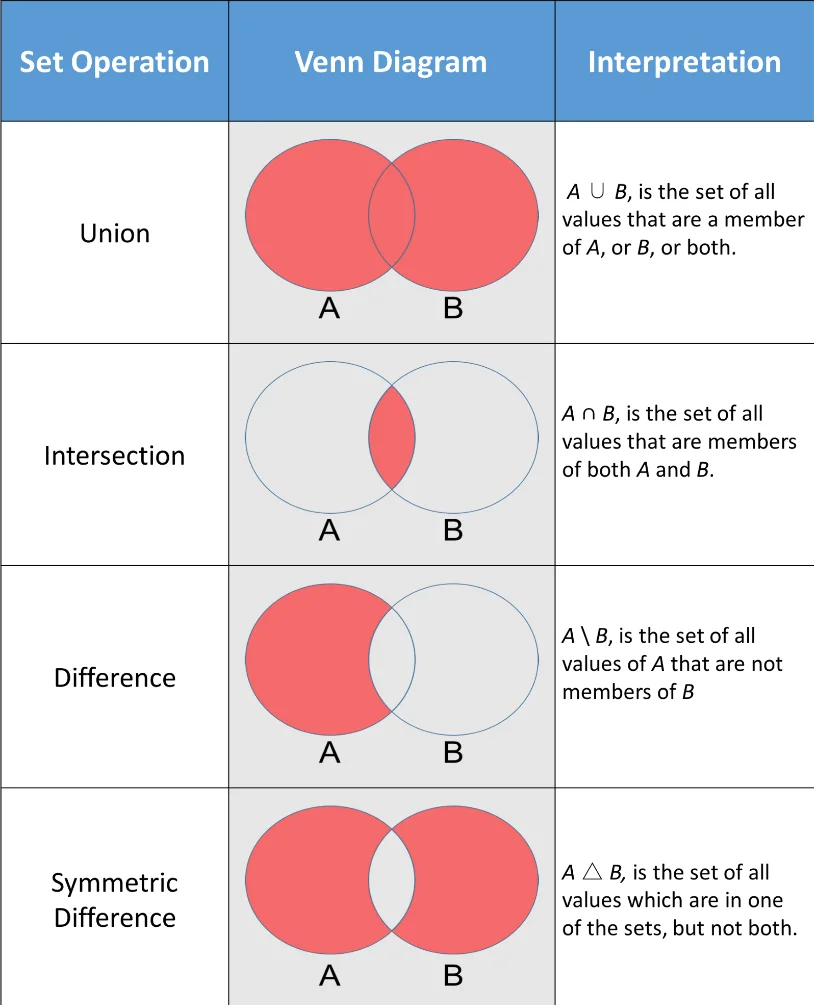
从属判断 ¶
s1.issubset(s2)来判断 s1 是否为 s2 的⼦集s2.issuperset(s1)来判断 s2 是否为 s1 的超集- 使⽤关系运算符
==和!=判断 2 个集合是否包含完全相同的元素。
示例 ¶
from matplotlib_venn import venn3
import matplotlib.pyplot as plt
set1 = {1,2,3} ## 等同于 set1=set((1,2,3))
set2 = {2,3,4}
set3 = {3,4,5}
# Use the venn3 function
venn3([set1,set2,set3], ('set1', 'set2','set3'))
plt.show()
##挑选名单
#要在 104 位同学中随机挑选 20 位参加周三上午的连麦分享,但是有 7 位同学已经在预定的名单中了
#输⼊数据:104 ⼈名单(学号)和 7 ⼈名单(学号)
#输出数据:20 ⼈名单和剩下的 84 ⼈名单
import random
ta = {'3190101849', '3190102191', '3190104143', '3190104515'
, '3190104602', '3190104958', '3190105360'}
md = set()
for i in range(104):
md.add(input())
md -= ta
tc = set(random.sample(md, 13)) # 随机取样
tc = tc | ta
print(*tc, sep='\n')
print('-'*80)
print(*(md-tc), sep=', ')
字典Dictionary ¶
- 字典是⼀个⽤“键”做索引来存储的数据的集合。⼀个键和它所对应的数据形成字典中的一个条目。
- 字典⽤花括号
{ }来表示,元素之间用逗号,分隔,每个元素⽤冒号分隔键和数据
字典的键
- 不可变对象可作为字典的键,如数字、字符串、元组
- 可变对象不可以作为字典的键,如:列表、字典等
创建 ¶
- 可以⽤ {} 或者 dict() 来创建空字典
- ⽤
{}或dict()创建字典
fac={'math': '0001', 'python': '0002', 'c': '0003'}
print(fac)
fac=dict([("math","0001"),("python","0002"),("c","0003")])
print(fac)
fac=dict(math="0001",python="0002",c="0003")
print(fac)
#json 将字符串转换为字典
import json
user_info= '{"name" : "john", "gender" : "male", "age": 28}'
user_dict = json.loads(user_info)
操作 ¶
- 删:
del
- 改
- 查:
in和not in
- 遍历:
for
###用 items() 实现字典遍历
score = {'张三':78, '李四':92, '王五':89}
for key,value in score.items():
print(f'{key}:{value}')
- 运算:⽤
==和!=⽐较两个字典是否相同(键和值都相同)
| 方法 | 功效 | |
|---|---|
keys() |
返回由全部的键组成的一个序列 |
values() |
返回由全部的值组成的一个序列 |
items() |
返回一个序列,其中的每一项是一个元组,每个元组由键和它对应的值组成 |
clear() |
删除所有条目 |
get(key,value) |
返回这个键所对应的值,如找不到返回value |
pop(key) |
返回这个键所对应的值,同时删除这个条目 |
- 函数
get()和运算符[ ]不同之处,在于如果键key在字典中不存在,则get(key)返回None值,⽽运算符[ ]会抛出KeyError异常 - 函数 keys()、values()、items() 都是返回⼀个迭代器可以被
for in遍历,由于字典中键不重复,所以keys()和items()的返回结果可以转换成集合⽽values()返回值由于可能存在重复值,应该转换为列表或元组
例子 ¶
##星期
days={1:"Mon",2:"Tue",3:"Wed",4:"Thu",5:"Fri",6:"Sat",7:"Sun"}
num=int(input())
print(days[num])
##四则运算
result={
"+":"x+y",
"-":"x-y",
"*":"x*y",
"/":'x/y if y!=0 else "divided by zero"'}
r=eval(result.get(z))
##统计各位数字次数
str=input()
countchar={}
for c in str:
countchar[c]=countchar.get(c,0)+1
print(countchar)
## sort by key
cnt = sorted(cnt.items(), key=lambda d: d[0], reverse=False)
## sort by value
cnt = sorted(cnt.items(), key=lambda d: d[1], reverse=False)
可以根据两个乘数,查阅字典得到乘积。以3的乘法为例:
d1={(3,1):3,(3,2):6,(3,3):9,(3,4):12,(3,5):15,(3,6):18,(3,7):21,(3,8):24, (3,9):27}
d1[(3,9)]
迭代器Iterator ¶
Python 迭代器遵循两个核心方法:
__iter__(): 返回迭代器对象本身
__next__(): 返回下一个元素,没有元素时抛出 StopIteration
iter¶
可使用iter函数的:序列、容器、iter本身
r = range(1,10)
s = iter(r)
next(s)
内置迭代器 ¶
# 列表
for item in [1, 2, 3]:
print(item)
# 字符串
for char in "hello":
print(char)
d = {'a': 1, 'b': 2}
# 键迭代
for key in d:
print(key)
# 值迭代
for value in d.values():
print(value)
# 键值对迭代
for k, v in d.items():
print(k, v)
with open('data.txt') as f:
for line in f: # 文件对象本身就是行迭代器
print(line.strip())
for index, value in enumerate(['a', 'b', 'c']):
print(index, value)
# 输出:
# 0 a
# 1 b
# 2 c
names = ['Alice', 'Bob']
ages = [25, 30]
for name, age in zip(names, ages):
print(name, age)
# 输出:
# Alice 25
# Bob 30
高级迭代器 ¶
mapzipfilter
# 惰性计算
squares = map(lambda x: x**2, [1, 2, 3])
print(list(squares)) # [1, 4, 9]
evens = filter(lambda x: x % 2 == 0, [1, 2, 3, 4])
print(list(evens)) # [2, 4]
for i in reversed(range(5)):
print(i) # 4, 3, 2, 1, 0
itertools模块 ¶
count(start, [ste[]):无穷计数cycle(p):循环遍历 prepeat(e, [n]):重复得到 e(可限制为 n 次)
from itertools import count
my_list =["Geeks", "for", "Geeks"]
for i in zip(count(start = 1, step = 1), my_list):
print(i)
| 迭代器 | 实参 | 结果 |
|---|---|---|
| product() | p, q, … [repeat=1] | 笛卡尔积,相当于嵌套的 for 循环 |
| permutations() | p[, r] | 长度 r 元组,所有可能的排列,无重复元素 |
| combinations() | p, r | 长度 r 元组,有序,无重复元素 |
| combinations_with_replacement() | p, r | 长度 r 元组,有序,元素可重复 |
| 例子 | 结果 |
|---|---|
| product('ABCD', repeat=2) | AA AB AC AD BA BB BC BD CA CB CC CD DA DB DC DD |
| permutations('ABCD', 2) | AB AC AD BA BC BD CA CB CD DA DB DC |
| combinations('ABCD', 2) | AB AC AD BC BD CD |
| combinations_with_replacement('ABCD', 2) | AA AB AC AD BB BC BD CC CD DD |
ranks = ['A', 'K', 'Q', 'J', '10', '9', '8', '7', '6', '5', '4', '3', '2'
suits = ['H', 'D', 'C', 'S']
# 生成器表达式版本
cards = ((suit, rank) for suit in suits for rank in ranks)
print(*cards)
# product 版本
import itertools as it
cards = it.product(suits, ranks)
print(*cards)
生成器Generator ¶
yield
preserve newly created environment for later call
when next is called, execution resumes where it left off
def simple_generator():
print("开始")
yield 1
print("继续")
yield 2
print("结束")
gen = simple_generator() # 创建生成器对象 (不执行函数体)
print(next(gen)) # 输出"开始",然后返回 1
print(next(gen)) # 输出"继续",然后返回 2
print(next(gen)) # 输出"结束",然后抛出 StopIteration
生成器表达式 ¶
圆括号、数据不存储、调⽤⼀次可以枚举⼀次
(expression for i in s if condition)
#把⽣成器表达式⽤作函数的参数值时,外⾯的圆括号可以省略
sum(x*x for x in range(10))
#但是当生成器表达式只是函数的参数之一时,必须有外面的圆括号
def fun(f, b):
for x in b:
f(x)
fun(print, x for x in range(10)) # Error
生成器函数 ¶
生成器函数是一种特殊类型的函数,使用 yield 关键字来生成序列的元素。当调用生成器函数时,并不立即执行函数体,而是返回一个生成器对象,通过调用生成器对象的 next() 方法来逐个生成元素。
def countdown(n):
while n > 0:
yield n
n -= 1
# 调用生成器函数
generator = countdown(5)
print(next(generator)) # 输出:5
print(next(generator)) # 输出:4
print(next(generator)) # 输出:3
print(next(generator)) # 输出:2
print(next(generator)) # 输出:1
生成器函数执行到 yield 关键字,函数会暂停执行并将生成的值返回给调用者。函数的状态会被保留,以便在下一次调用 next() 方法时可以继续执行。当函数执行结束或遇到 return 语句时,生成器对象会引发 StopIteration 异常,表示序列已经生成完毕。
应用 ¶
def read_large_file(file_path):
with open(file_path) as f:
for line in f:
yield line.strip()
# 逐行处理,不一次性加载整个文件
for line in read_large_file("huge_file.txt"):
process(line)
def infinite_sequence():
num = 0
while True:
yield num
num += 1
for i in infinite_sequence():
if i > 100:
break
print(i)
def pipeline(data):
# 第一阶段处理
processed = (x.upper() for x in data if x.strip())
# 第二阶段处理
filtered = (x for x in processed if not x.startswith("A"))
yield from filtered # Python 3.3+ 语法
data = ["apple", " banana", "orange", " pear"]
print(list(pipeline(data))) # [' BANANA', 'ORANGE', ' PEAR']
优点 ¶
- 节省内存,惰性求值
- 可以实现协程和异步编程