02 | Linear Regression
5616 4 张图片 22
OLS - 优化视角考虑经典的线性回归模型:
\[
y = X \beta + \varepsilon, \quad \varepsilon \sim \mathcal{N}(0, \sigma^2 I_n)
\]
其中:
\(y \in \mathbb{R}^n\) :响应变量\(X \in \mathbb{R}^{n \times p}\) :满秩设计矩阵(列满秩)\(\beta \in \mathbb{R}^p\) :未知回归系数\(\varepsilon\) :独立同分布噪声,均值 0 \(\sigma^2\)
残差平方和(Residual Sum of Squares, RSS)定义为:
\[
RSS = \sum_{i=1}^n \left( y_i - x_{i1}\beta_1 - \cdots - x_{ip}\beta_p \right)^2
\]
也可以写成向量形式:
\[
RSS = \|\mathbf{y} - \mathbf{X}\boldsymbol{\beta}\|^2 = (\mathbf{y} - \mathbf{X}\boldsymbol{\beta})^\mathsf{T}(\mathbf{y} - \mathbf{X}\boldsymbol{\beta})
\]
最小二乘估计(Ordinary Least Squares, OLS)就是选择使 RSS \(\boldsymbol{\beta}\)
\[
\widehat{\beta} = \underset{\boldsymbol{\beta}}{\operatorname*{arg\,min}} \; (\mathbf{y} - \mathbf{X}\boldsymbol{\beta})^\mathsf{T}(\mathbf{y} - \mathbf{X}\boldsymbol{\beta})
\]
To estimate \(\beta\) , we set the derivative equal to 0
$\(\frac{\partial \text{RSS}}{\partial \beta} = -2 \mathbf{X}^\top (\mathbf{y} - \mathbf{X} \beta) = 0\) $
\[
\widehat{\beta} = (\mathbf{X}^\top \mathbf{X})^{-1} \mathbf{X}^\top \mathbf{y}
\]
\(\mathbf{X}\) full rank \(\iff \mathbf{X}^\top \mathbf{X}\) invertible
性质
\[
\hat{\beta} = (X^T X)^{-1} X^T y
\]
无偏
我们计算 \(\mathbb{E}[\hat{\beta}]\)
\[
\begin{aligned}
\mathbb{E}[\hat{\beta}] &= \mathbb{E}[(X^T X)^{-1} X^T y] \\
&= (X^T X)^{-1} X^T \mathbb{E}[y] \\
&= (X^T X)^{-1} X^T (X\beta) \\
&= (X^T X)^{-1} X^T X \beta \\
&= \beta
\end{aligned}
\]
方差
将 \(\mathbf{y} = \mathbf{X} \boldsymbol{\beta} + \boldsymbol{\varepsilon}\)
\[
\hat{\boldsymbol{\beta}} = (\mathbf{X}^\top \mathbf{X})^{-1} \mathbf{X}^\top (\mathbf{X} \boldsymbol{\beta} + \boldsymbol{\varepsilon}) \\
= \boldsymbol{\beta} + (\mathbf{X}^\top \mathbf{X})^{-1} \mathbf{X}^\top \boldsymbol{\varepsilon}
\]
有
\[
\begin{aligned}
\operatorname{Var}(\hat{\boldsymbol{\beta}})
&= \operatorname{Var} \left( (\mathbf{X}^\top \mathbf{X})^{-1} \mathbf{X}^\top \boldsymbol{\varepsilon} \right) \\
&= (\mathbf{X}^\top \mathbf{X})^{-1} \mathbf{X}^\top \operatorname{Var}(\boldsymbol{\varepsilon}) \mathbf{X} (\mathbf{X}^\top \mathbf{X})^{-1} \\
&= \sigma^2 (\mathbf{X}^\top \mathbf{X})^{-1} \mathbf{X}^\top \mathbf{X} (\mathbf{X}^\top \mathbf{X})^{-1} \\
&=\boxed{ \sigma^2 (\mathbf{X}^\top \mathbf{X})^{-1} }\\
&= \widehat{\sigma}^2 (\mathbf{X}^\top \mathbf{X})^{-1} \quad \text{(可用残差平方和估计)} \\
&= \frac{RSS}{n - p} (\mathbf{X}^\top \mathbf{X})^{-1} \\
&= \frac{1}{n - p} \sum_{i=1}^n \hat{\varepsilon}_i^2 (\mathbf{X}^\top \mathbf{X})^{-1}
\end{aligned}
\]
UMVUE
Lehmann–Scheffé 定理告诉我们:
若某无偏估计量是充分统计量的函数,则它是 UMVUE
我们来验证:
1️⃣ \(\hat{\beta}\) \(\beta\)
已证
2️⃣ \(X^T y\)
由因子分解定理 :
\(y \sim \mathcal{N}(X\beta, \sigma^2 I)\) 联合密度函数可以写成关于 \(X^T y\) \(\beta\)
所以 \(X^T y\) \(\beta\)
而 \(\hat{\beta}\) \(X^T y\) 充分统计量的函数
✅ 满足 LehmannScheffé 定理条件 ⇒ 是 UMVUE
或者你也可以使用 Gauss-Markov
Gauss-Markov 定理
在线性模型中,在所有线性无偏估计量中,OLS 是方差最小的。
\[
Ax = b + \epsilon
\]
噪声 \(\epsilon\)
\[
\begin{align*}
\mathbb{E}(\epsilon) &= 0\\
Cov(\epsilon) &= \mathbb{E}[\epsilon \epsilon^T] = \sigma^2 I
\end{align*}
\]
内含的假设:误差的干扰源是独立的
\[
\hat{x}_{LS} = (A^T A)^{-1} A^T b
\]
OLS 最小二乘估计是 \(x\)
即满足
\[
\begin{align*}
\mathbb{E}[\hat{x}_{LS}] &= \mathbb{E}\left[(A^T A)^{-1} A^T b\right] \\
&= (A^T A)^{-1} A^T \mathbb{E}(Ax - \epsilon) \\
&= (A^T A)^{-1} A^T A x \\
&= x\\
Var(\hat{x}_{LS}) &\leq Var(\tilde{x})
\end{align*}
\]
但要注意:
Gauss-Markov 定理 → 最优线性无偏估计(BLUE)Lehmann–Scheffé 定理(+ 正态性)→ 最小方差无偏估计(UMVUE)
Training Error & Test Error
\[
\begin{aligned}
\mathbb{E}[\mathrm{TestErr}] &= \mathbb{E}\|\mathbf{y}^*-\mathbf{X}\widehat{\beta}\|^2 \\
&= \mathbb{E}\|(\mathbf{y}^*-\mathbf{X}\beta)+(\mathbf{X}\beta-\mathbf{X}\widehat{\beta})\|^2 \\
&= \mathbb{E}\|\mathbf{y}^*-\mu\|^2 + \mathbb{E}\|\mathbf{X}(\widehat{\beta}-\beta)\|^2 \\
&= \mathbb{E}\|\mathbf{e}^*\|^2 + \mathrm{Trace}(\mathbf{X}^\mathsf{T}\mathbf{X}\,\mathrm{Cov}(\widehat{\beta})) \\
&= n\sigma^2 + p\sigma^2
\end{aligned}
\]
\[
\begin{aligned}
\mathbb{E}[\mathrm{TrainErr}] &= \mathbb{E}\|\mathbf{y}-\mathbf{\widehat{y}}\|^2 = \mathbb{E}\|(\mathbf{I}-\mathbf{H})\mathbf{y}\|^2 \\
&= \mathbb{E}\|(\mathbf{I}-\mathbf{H})\mathbf{e}\|^2 \\
&= \mathrm{Trace}\left((\mathbf{I}-\mathbf{H})^\mathsf{T}(\mathbf{I}-\mathbf{H})\,\mathrm{Cov}(\mathbf{e})\right) \\
&= (n-p)\sigma^2
\end{aligned}
\]
OLS - 统计视角
观测出模型的假设非常关键,给人判定模型好坏的一个直观的方法
首先定义拟合误差:
\[
Az = b + e
\]
其中假设噪声 \(e\)
使用高斯噪声的建模假设:模型的预测能力是比较好的,没有 outlier \(3\sigma\) ) ,比如上课一次不来,作业一次不交,考试考 100
在这种时候使用高斯噪声建模,可以得到一个比较好的结果
\[
e \sim N(e|0,\sigma^{2}I) \propto \exp\left[-\frac{1}{\sigma^{2}}\mathrm{e}^{\mathrm{H}}e\right]
\]
因此条件概率可以写作:
\[
p(b | Ax) = N(b|Ax,\sigma^{2}I)\\
= \frac{1}{z}\exp\left[-\frac{(b-Ax)^T(b-Ax)}{\sigma^2}\right]
\]
根据极大似然估计,我们需要找到一个 \(z\) \(p(b|Az)\)
\[
\begin{aligned}
\max\ \log p(b|Az) &\Leftrightarrow \max\ \log \frac{1}{z}\exp\left[-\frac{(b-Ax)^T(b-Ax)}{\sigma^2}\right]\\
&= \max\ \log \frac{1}{z} -\frac{(b-Ax)^T(b-Ax)}{\sigma^2} \\
&= \min\ \frac{(b-Ax)^T(b-Ax)}{\sigma^2}\\
&= \min \ (b-Ax)^T(b-Ax)\\
&= \min \ \|Ax-b\|_2^2
\end{aligned}
\]
conditional pdf 对 b
likelihood function 对 z
DLS - 最小数据二乘假设数据矩阵 \(A\)
\[
A = A_0 + E \\
E_{ij} \stackrel{\text{i.i.d.}}{\sim} N(0, \sigma^2)
\]
使用校正量 \(\Delta A\)
\[
\begin{align*}
\min \quad & ||\Delta A||^2_F\\
s.t. \quad &\left[ A + \Delta A \right] x = b
\end{align*}
\]
underlying idea: 每个数据的误差不会特别大
Frobenius 范数 \((p=2)\)
\[
\|A\|_F \stackrel{\text{def}}{=} \left( \sum_{i=1}^m \sum_{j=1}^n |a_{ij}|^2 \right)^{1/2} = \sqrt{\text{trace}(AA^H)}
\]
对于有约束问题,写出拉格朗日函数
\[
\begin{align*}
L(A, \lambda) &= \|A\|_F^2 + \lambda^H \left[(A + \Delta A)x - b\right]\\
&= Trace(AA^H) + \lambda^H \left[(A + \Delta A)x - b\right]
\end{align*}
\]
求导数并令导数为 0
\[
\begin{align*}
\frac{\partial L(A, \lambda)}{\partial \Delta A} &= \Delta A^H + \lambda x^H = 0\\
\frac{\partial L(A, \lambda)}{\partial \lambda^H} &= (A + \Delta A)x - b = 0
\end{align*}
\]
可以解出
\[
\Delta A = - \frac{(Ax-b)x^H}{x^H x}\quad \lambda = \frac{Ax-b}{x^H x}
\]
把 \(\Delta A\) \(\lambda\) \(L(A, \lambda)\)
\[
L(\Delta A, \lambda,x) = \frac{(Ax-b)^H (Ax-b)}{x^H x}
\]
变成了一个无约束的优化问题
\[
\min_x J(x) =\frac{(Ax-b)^H (Ax-b)}{x^H x}
\]
方法 1: \(x^{t+1} = x^t - \eta \nabla J(x^t)\)
方法 2: (Fractional Programming)
\[
\begin{align*}
\max_{x ,y} & \quad x^H y \\
\mathrm{s.t.} & \quad y = \frac{x}{(Ax-b)^H(Ax-b)}
\end{align*}
\]
\[
\min_{x, y} \|y\|_2^2 x^H A A^H x - 2 \mathrm{Re} \left\{ \|y\|_2^2 b^H A x \right\} + \|y\|_2^2 b^H b - 2 y^H x
\]
Fix \(x\) , 那么 \(y\) Fix \(y\) , 那么 \(x\)
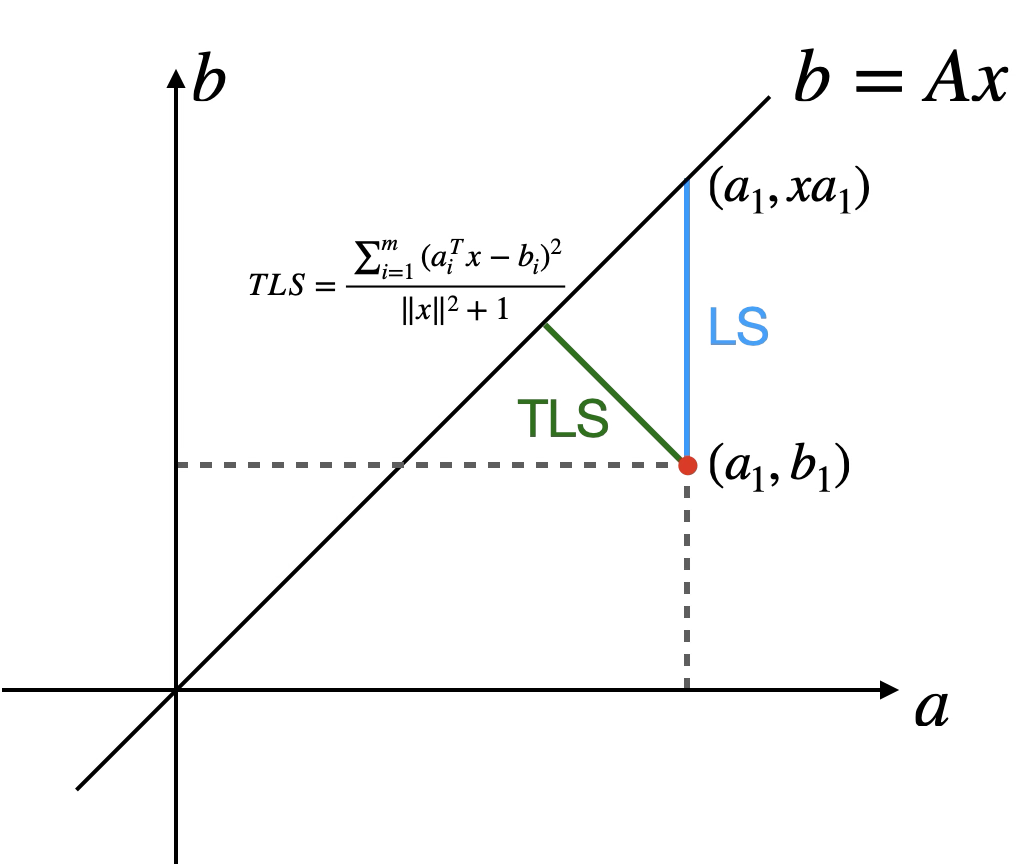
TLS - 总体最小二乘优化问题 :纠正最小 \(\Delta A\) \(\Delta b\)
步骤
input \(A\) 和 \(b\) 增广矩阵 \(B = \begin{bmatrix} A & b \end{bmatrix}\)
\(B^HB = V \Sigma V^H\) 找 \(\lambda_{min}\) \(v_{min}\)
\(z^{\star} = v_{min} \times \frac{-1}{v_ {n+1}}\)
问题求解
\[
\begin{align*}
\min_{\Delta A, \Delta b,x} \quad & ||\Delta A||^2_F + ||\Delta b||^2\\
s.t. \quad &\left[ A + \Delta A \right] x = b + \Delta b
\end{align*}
\]
写成分块矩阵的形式
\[
\begin{bmatrix}A & b\end{bmatrix}\begin{bmatrix} x \\ -1 \end{bmatrix} +\begin{bmatrix} \Delta A & \Delta b \end{bmatrix} \begin{bmatrix} x \\ -1 \end{bmatrix} = 0
\]
令
\[
B = \begin{bmatrix} A & b \end{bmatrix} \quad D = \begin{bmatrix} \Delta A & \Delta b \end{bmatrix} \quad z = \begin{bmatrix} x \\ -1 \end{bmatrix}
\]
所以原始问题可以写成
\[
\begin{align*}
\min_{\Delta A, \Delta b,x} \quad & \|\mathbf{D}\|_F^2 \\
\text{s.t.} \quad &(\mathbf{B} + \mathbf{D})z = 0
\end{align*}
\]
可以看出,TLS 是 DLS \(b = 0\)
使用拉格朗日乘子法
\[
\begin{align*}
\min_{z} \quad & \frac{(Bz-0)^H (Bz-0)}{z^H z} \\
=\; & \min_{z} \frac{z^H B^H B z}{z^H z}
\end{align*}
\]
两个二次型相除:Rayleigh 商,有闭式解(在 PCA TLS
对 \(B^HB = V \Sigma V^H\)
那么最优解 \(z^{\star} = \begin{bmatrix} x^{\star} \\ -1 \end{bmatrix} = v_{min}\)
但是这里存在一个问题:\(v_{min}\) \(-1\) , \(-1\)
\[
\frac{-1}{v_{n+1}} V_{min}= \begin{bmatrix} \frac{-v_1}{v_{n+1}} \\ \frac{-v_2}{v_{n+1}} \\ \vdots \\ \frac{-v_n}{v_{n+1}} \\ -1 \end{bmatrix} = \begin{bmatrix} x^{\star} \\ -1 \end{bmatrix}
\]
几何含义
普通 LS
而 TLS ;
\[
\begin{align*}
\min_{z} \frac{z^H B^H B z}{z^H z}
=\;&\frac{
\begin{bmatrix}
x \\ -1
\end{bmatrix}^H
\left(
\begin{bmatrix}
A & b
\end{bmatrix}^H
\begin{bmatrix}
A & b
\end{bmatrix}
\right)
\begin{bmatrix}
x \\ -1
\end{bmatrix}
}{
\begin{bmatrix}
x \\ -1
\end{bmatrix}^H
\begin{bmatrix}
x \\ -1
\end{bmatrix}
} \\
=\; & \frac{ \|A_{\color{red}m\times n}x_{\color{red}n\times 1}-b_{\color{red}m\times 1}\|_2^2 }{ \|x_{\color{red}n\times 1}\|_2^2 + 1 }\\
=\; &\frac{\sum_{i=1}^{m}(a_i^Tx-b_i)^2}{\|x\|^2+1} \quad \text{矩阵的行视角}
\end{align*}
\]
点到直线距离公式
假设点 \(P(x_1, y_1)\) \(Ax + By + C = 0\) \(d\)
\[
d = \frac{|Ax_1 + By_1 + C|}{\sqrt{A^2 + B^2}}
\]
对于直线 \(Ax -b = 0\) \(A\) \(b\) \((a_1,b_1)\) \(b = Ax\)
\[
d^2 = \frac{|Ax -b|^2}{x^2 + 1}
\]
引理:TLS 拟合直线一定过 \((\bar{x}, \bar{y})\)
\[
\bar{x} = \frac{\sum_{i=1}^{N} x_i}{n}\qquad
\bar{y} = \frac{\sum_{i=1}^{N} y_i}{n}
\]
设直线方程为 \(ax+by+c =0\) , \((\bar{x},\bar{y})\) \(a\bar{x}+b\bar{y} + c =0 \leftrightarrow c = -a\bar{x} - b \bar{y}\)
带入原来的方程可得 \(a(x-\bar{x}) + b (y - \bar{y}) = 0\)
为了减少参数量,使用重参数化技巧,令
\[
k = \frac{-a}{b}
\]
得到
\[
k(x-\bar{x}) + (y - \bar{y}) = 0
\]
假设我们有点集 \((x_i,y_i)\)
那么即有
\[
\begin{bmatrix}
x_1 - \bar{x}\\
x_2 - \bar{x}\\
\cdots\\
x_n - \bar{x}
\end{bmatrix}
k = \begin{bmatrix}y_1 - \bar{y}\\y_2 - \bar{y}\\\cdots\\y_n - \bar{y}\end{bmatrix}\\
Ak = b
\]
求解案例
假设有点 \((2,1),(2,4),(5,1)\)
\(\bar{x} = 3,\bar{y} = 2\)
\[
\begin{align*}
B &= \begin{bmatrix}2-3 & 1-2\\ 2-3 & 4-2\\ 5-3 & 1-2\end{bmatrix} = \begin{bmatrix}-1 & -1\\ -1 & 2\\ 2 & -1\end{bmatrix}\\
B^{H}B &= \begin{bmatrix}-1 & -1 & 2\\ -1 & 2 & -1\end{bmatrix} \begin{bmatrix}-1 & -1\\ -1 & 2\\ 2 & -1\end{bmatrix}= \begin{bmatrix}6 & -3\\ -3 & 6\end{bmatrix}\\
V_{\min} &= \begin{bmatrix}\frac{1}{\sqrt{2}}\\ \frac{1}{\sqrt{2}}\end{bmatrix}\\
z &= \begin{bmatrix}-1\\ -1\end{bmatrix}=\begin{bmatrix}k\\-1\end{bmatrix}\quad \text{进行归一化}
\end{align*}
\]
\[
\begin{align*}
\therefore k &= -1\\
&-(x-3) = y-2\\
y &= -x +5
\end{align*}
\]
Rayleigh 商的应用场景 —— 最大信噪比的接收滤波器设计
\[
r(t) = BS(t) +noise(t)
\]
\(r(t)\) \(S(t)\) \(noise(t)\)
signal-to-noise ratio
设计滤波器,使得输出信噪比 SNR
\[
\underset{\text{filter output}}{x^H r(t)} = \underset{\text{signal}}{x^H B s(t)} + \underset{\text{noise}}{x^H n(t)}
\]
\[
\mathrm{SNR} = \frac{\mathbb{E}\left[\,|x^H B s(t)|^2\,\right]}{\mathbb{E}\left[\,|x^H n(t)|^2\,\right]} = \frac{x^H B\, \mathbb{E}\left[\underset{发射信号协方差}{S(t)S^H(t)}\right] B^H x}{x^H\, \mathbb{E}\left[\underset{噪声协方差}{n(t)n^H(t)}\right] x}
\]
如果建模噪声是白噪声,彼此正交;且认为信号也是彼此正交的
即
\(E(s(t)s^H(t)) = \alpha I\) \(E(n(t)n^H(t)) = \beta I\)
\[
\mathrm{SNR} = \frac{\alpha x^H B B^H x}{\beta x^H x}
\]
得到了 Rayleigh
如果要 maximize SNR \(B B^H\)
广义线性回归
logistic
线性回归有一个很强的假设,就是 y (MSE function)
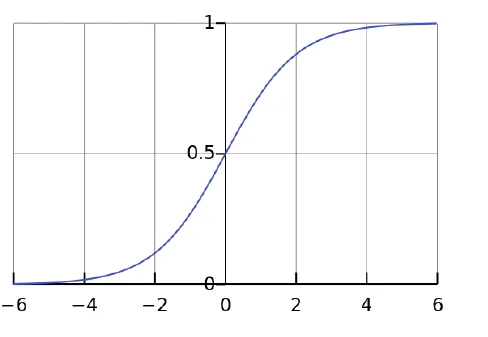
logistic function:
sigmoid function: \(f(x) = \frac{1}{1+e^{-x}}\)
CDF(累积分布函数)ofthe standard logistic distribution
使用 sigmoid 函数将线性回归的输出转换为概率
logistic Regreesion 是一个线性模型
主要考虑的是 decision boundary
为什么 loss function log
为了方便求导
取 log
Assumptions behind logistic regression
\(l(a) = -\sum_{i\in I} \log(1+e^{-y_i a^T x_i})\)
pros:
binomial distribution is a good assumption for classification
provide a probability
low computation, easy to optimize
support online learning: 梯度下降的模型都支持在线学习
cons:
too simple:high bias & low variance
对于分类问题,只关心分类正确的类的值
Penalty
A unified framework is to minimize the objective function
\[
\arg\min_{\beta} \frac{1}{2n}\|\mathbf{y}-\mathbf{X}\boldsymbol{\beta}\|^2 + \sum_{j=1}^p P_{\lambda}(\beta_j)
\]
where \(P_{\lambda}(\cdot)\) is a penalty function applied on the value of each parameter, and \(\lambda\) is a tuning parameter.
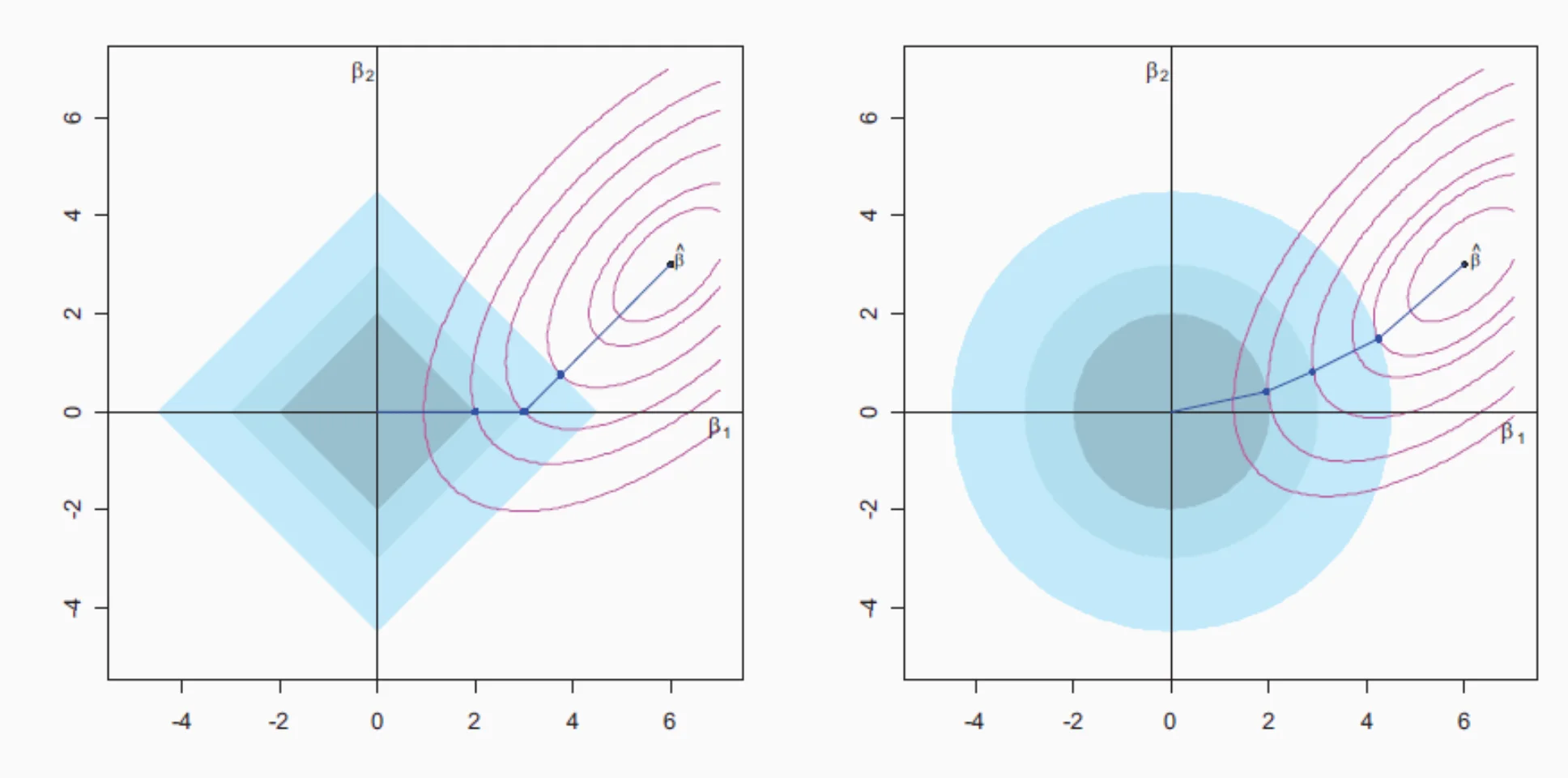
Lasso: \(P_{\lambda}(\beta) = \lambda|\beta|\)
Ridge: \(P_{\lambda}(\beta) = \lambda\beta^2\)
Best subset: \(P_{\lambda}(\beta) = \lambda\mathbf{1}\{\beta \neq 0\}\)
Elastic net: \(P_{\lambda}(\beta) = \lambda_1|\beta| + \lambda_2\beta^2\)
Lasso - l1
核心内容
解释
Oracle Property
同时实现变量选择一致性 +
Lasso 的问题有偏差,不能同时实现两者
理论上条件
为了选变量,\(\lambda\) \(\lambda\) 0
解决方法
改用无偏惩罚函数(如 SCAD) ,或者接受一定折中
求解下面的优化问题
\[
\begin{aligned}
& \text{minimize } \sum_{i=1}^{n} \left(y_i - \sum_{j=1}^{p} \beta_j x_{ij}\right)^2 \\
& \text{subject to } \sum_{j=1}^{p} |\beta_j| \leq s
\end{aligned}
\]
Each value of \(\lambda\) corresponds to an unique value of \(s\) .
Lasso 回归在正交设计下的推导与原理假设:
设计矩阵满足 \(\mathbf{X}^\top \mathbf{X} = \mathbf{I}_p\)
目标是求解 Lasso
\[
\widehat{\boldsymbol{\beta}}^{\text{lasso}} = \arg\min_{\boldsymbol{\beta}} \|\mathbf{y} - \mathbf{X} \boldsymbol{\beta}\|^2 + \lambda \|\boldsymbol{\beta}\|_1
\]
步骤 1 OLS
因为 OLS
\[
\widehat{\boldsymbol{\beta}}^{\text{ols}} = \mathbf{X}^\top \mathbf{y}
\]
我们将其插入目标函数:
\[
\begin{align*}
\|\mathbf{y} - \mathbf{X} \boldsymbol{\beta}\|^2 &= \|\mathbf{y} - \mathbf{X} \widehat{\boldsymbol{\beta}}^{\text{ols}} + \mathbf{X} \widehat{\boldsymbol{\beta}}^{\text{ols}} - \mathbf{X} \boldsymbol{\beta}\|^2\\
&= \|\mathbf{y} - \mathbf{X} \widehat{\boldsymbol{\beta}}^{\text{ols}}\|^2 + \|\mathbf{X} \widehat{\boldsymbol{\beta}}^{\text{ols}} - \mathbf{X} \boldsymbol{\beta}\|^2 + 2 \underbrace{(\mathbf{y} - \mathbf{X} \widehat{\boldsymbol{\beta}}^{\text{ols}})^\top (\mathbf{X} \widehat{\boldsymbol{\beta}}^{\text{ols}} - \mathbf{X} \boldsymbol{\beta})}_{=0}
\end{align*}
\]
其中最后一项为 0
残差 \(\mathbf{r} = \mathbf{y} - \mathbf{X} \widehat{\boldsymbol{\beta}}^{\text{ols}}\) \(\operatorname{Col}(\mathbf{X})\)
而 \(\mathbf{X}(\widehat{\boldsymbol{\beta}}^{\text{ols}} - \boldsymbol{\beta}) \in \operatorname{Col}(\mathbf{X})\)
步骤 2
因为第一项与 \(\boldsymbol{\beta}\) +
\[
\min_{\boldsymbol{\beta}} \|\mathbf{X} \widehat{\boldsymbol{\beta}}^{\text{ols}} - \mathbf{X} \boldsymbol{\beta}\|^2 + \lambda \|\boldsymbol{\beta}\|_1\\
\leftrightarrow \min_{\boldsymbol{\beta}} \|\widehat{\boldsymbol{\beta}}^{\text{ols}} - \boldsymbol{\beta}\|^2 + \lambda \|\boldsymbol{\beta}\|_1 \quad (\because\mathbf{X}^\top \mathbf{X} = \mathbf{I})
\]
变量独立求解
目标函数可分解为每个参数的独立优化:
\[
\widehat{\beta}_j^{\text{lasso}} = \arg\min_{x} (x - a)^2 + \lambda |x|, \quad a = \widehat{\beta}_j^{\text{ols}}
\]
这就是经典的 Soft Thresholding 问题
\[
\boxed{
\widehat{\beta}_j^{\text{lasso}} = \operatorname{sign}(a) \cdot \max(|a| - \lambda/2, 0)
}
\]
即:
如果 \(|a| \leq \lambda/2\) 0
否则,在方向上缩减 \(\lambda/2\)
Soft Thresholding = 变量选择机制
Ridge 回归使用 \(\ell_2\) 0Lasso 使用 \(\ell_1\) 0所以 Lasso 变量选择(sparsity)
项目
解释
正交设计
\(\mathbf{X}^\top \mathbf{X} = \mathbf{I}\)
拆分误差项
残差项垂直于列空间,交叉项为 0
可分解目标
可对每个 \(\beta_j\)
Soft Threshold 解
稀疏性来源
系数可能直接为 0
\(\lambda\) 越多的参数会被压成 0
Ridge - l2
视角
解释
最优化视角
Ridge 解是最小化 \(\|\mathbf{y} - \mathbf{X}\boldsymbol{\beta} \|^2 + \lambda \|\boldsymbol{\beta}\|^2\)
贝叶斯视角
Ridge 解是 \(\boldsymbol{\beta} \sim \mathcal{N}(0, \frac{\sigma^2}{\lambda} \mathbf{I})\)
PCA 视角
优化视角
最优化视角,即求解下面的最优化问题
\[
(y - X\beta)^{\top}(y - X\beta) + \lambda\beta^{\top}\beta
\]
Take derivative with respect to \(\beta\) and set to zero
\[
\begin{aligned}
\widehat{\beta}^{\mathrm{~ridge}}&= \boxed{(X^{\top}X + \lambda I)^{-1}X^{\top}y}\\&=(\mathbf{X}^\mathsf{T}\mathbf{X}+\lambda\mathbf{I})^{-1}(\mathbf{X}^\mathsf{T}\mathbf{X})(\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\mathbf{y}\\&=(\mathbf{X}^\mathsf{T}\mathbf{X}+\lambda\mathbf{I})^{-1}(\mathbf{X}^\mathsf{T}\mathbf{X})\widehat{\boldsymbol{\beta}}^\mathsf{ols}\\&=\mathbf{Z}\widehat{\boldsymbol{\beta}}^{\mathrm{ols}}
\end{aligned}
\]
PCA 视角
SVD 分解
\[
\mathbf{X} = U D V^\top
\]
\(U\) :正交列向量,表示在数据空间中的方向(主成分)\(D\) :奇异值(与协方差矩阵特征值相关)\(V\) :输入空间的正交基(回归系数方向)
将协方差矩阵写成 PCA
\[
\frac{1}{n} \mathbf{X}^\top \mathbf{X} = V D^2 V^\top
\]
说明协方差的主方向(特征向量)就是 \(V\) \(d_j^2\)
第 \(j\) \(X v_j = d_j u_j\)
大的奇异值方向:数据方差大,保留信息多
小的奇异值方向:容易过拟合,要强烈惩罚
Ridge 回归对响应变量的估计:
\[
\mathbf{X} \hat{\boldsymbol{\beta}}^{\text{ridge}} = \sum_{j=1}^p u_j \cdot \frac{d_j^2}{d_j^2 + \lambda} \cdot u_j^\top \mathbf{y}
\]
把 \(\mathbf{y}\) \(u_j\)
投影结果 \(u_j^\top y\) 缩小 了一个因子 \(\frac{d_j^2}{d_j^2 + \lambda}\)
\(d_j^2\)
主题
内容
有偏性
Ridge 有偏,但可控制偏差
方差降低
Ridge 显著减少估计方差
MSE 更优合适的 \(\lambda\) MSE OLS
几何理解
Ridge 在 PCA shrinkage
实用价值
尤其在高维 /
贝叶斯视角
📌 先验假设
我们将回归系数 \(\boldsymbol{\beta}\)
\[
\boldsymbol{\beta} \sim \mathcal{N}\left(0, \frac{\sigma^2}{\lambda} \mathbf{I} \right)
\]
这是一个零均值、高斯先验,对每个参数都做了 \(\ell_2\)
🎯 似然函数(来自线性模型)
\[
\mathbf{y} \mid \boldsymbol{\beta} \sim \mathcal{N}(\mathbf{X}\boldsymbol{\beta}, \sigma^2 \mathbf{I})
\]
🧠 后验分布
利用贝叶斯定理(高斯 + ) ,得到后验分布为:
\[
\boldsymbol{\beta} \mid \mathbf{y} \sim \mathcal{N}\left( \underbrace{(\mathbf{X}^\top \mathbf{X} + \lambda \mathbf{I})^{-1} \mathbf{X}^\top \mathbf{y}}_{\text{ridge 解}}, \; \text{协方差矩阵} \right)
\]
其中后验 均值 正是 Ridge
\[
\boxed{
\mathbb{E}[\boldsymbol{\beta} \mid \mathbf{y}] = (\mathbf{X}^\top \mathbf{X} + \lambda \mathbf{I})^{-1} \mathbf{X}^\top \mathbf{y}
}
\]
Tikhonov 正则化对于 OLS
\[
\min_x \|Ax-b\|_2^2
\]
\[
x_{LS} = (A^T A)^{-1} A^T b
\]
但是如果 \(A\) \((A^T A)^{-1}\) \(x_{LS}\)
很直观的想法是让 \(A^{H}A\)
\[
\hat{x} = (A^{H}A + \lambda I)^{-1}A^{H}b
\]
(Bayesian Linear Regression)
Tikhonov 证明求下面的优化问题和上面的等价
\[
\min_x J(x) = \|Ax-b\|_2^2 + \lambda \|x\|_2^2, \quad \lambda \geq 0
\]
证明一下
\[
J(x)=||Ax-b||_{2}^{2}+\lambda||x||_{2}^{2}
\]
求解共轭梯度
\[
\frac{\partial J(x)}{\partial x^{*}}=A^{H}Ax-A^{H}b+\lambda x=0\\
(A^{H}A+\lambda I)x=A^{H}b
\]
解得
\[
\hat{x}_{Tik}=(A^{H}A+\lambda I)^{-1}Ab
\]
代价函数对应的是 likelihood
正则项对应的是 prior
bias
Ridge 回归是有偏估计
\[
\mathbb{E}[\hat{\boldsymbol{\beta}}^{\text{ridge}}] = Z \boldsymbol{\beta}, \quad Z = (\mathbf{X}^\top \mathbf{X} + \lambda \mathbf{I})^{-1} \mathbf{X}^\top \mathbf{X}
\]
因为 \(Z \neq I\) ridge 有偏的
随着正则化参数 \(\lambda\) bias² 增加
这是偏差 -
variance
\[
\begin{align*}
\operatorname{Var}\left(\widehat{\boldsymbol{\beta}}^{\text{ ridge}}\right) &= \operatorname{Var}\left(\mathbf{Z}\widehat{\boldsymbol{\beta}}^{\mathrm{ols}}\right) \\
&= {\color{red}Z}\operatorname{Var}\left(\widehat{\boldsymbol{\beta}}^{\mathrm{ols}}\right) {\color{red}Z^T}\\
&= {\color{red}(\mathbf{X}^\mathsf{T}\mathbf{X}+\lambda\mathbf{I})^{-1}(\mathbf{X}^\mathsf{T}\mathbf{X})}\sigma^2(X^TX)^{-1}{\color{red}(\mathbf{X}^\mathsf{T}\mathbf{X})(\mathbf{X}^\mathsf{T}\mathbf{X}+\lambda\mathbf{I})^{-1}}\\
&=\sigma^{2}\left(\mathbf{X}^{\top} \mathbf{X}+\lambda \mathbf{I}\right)^{-1} \mathbf{X}^{\top} \mathbf{X}\left(\mathbf{X}^{\top} \mathbf{X}+\lambda \mathbf{I}\right)^{-1}
\end{align*}
\]
总体方差是一个关于正则化强度 \(\lambda\) 单调递减函数
\[
\text{Total Variance} = \operatorname{Tr}\left( \operatorname{Var}\left(\hat{\boldsymbol{\beta}}^{\text{ridge}} \right) \right)
= \sigma^2 \cdot \operatorname{Tr} \left[ \left( X^T X + \lambda I \right)^{-1} X^T X \left( X^T X + \lambda I \right)^{-1} \right]
\]
记 \(\mathbf{S} = X^T X\)
我们可以对它做特征值分解 (因为它对称) :
\[
\mathbf{S} = Q \Lambda Q^\top, \quad \text{其中 } \Lambda = \text{diag}(\lambda_1, \ldots, \lambda_p), \lambda_i > 0
\]
于是整个方差矩阵可以化简为:
\[
\operatorname{Var}(\hat{\boldsymbol{\beta}}^{\text{ridge}})
= \sigma^2 Q \cdot \text{diag} \left( \frac{\lambda_i}{(\lambda_i + \lambda)^2} \right) \cdot Q^\top
\]
所以其 trace
\[
\text{Total Variance} = \sigma^2 \sum_{i=1}^p \frac{\lambda_i}{(\lambda_i + \lambda)^2}
\]
总体方差是一个关于正则化强度 \(\lambda\) 单调递减函数
换句话说,正则化越强 ⇒ 系数波动越小
自由度
dof
\[
\text{df}(\hat{f}) = \frac{1}{\sigma^2} \sum_{i=1}^n \operatorname{Cov}(\hat{y}_i, y_i) = \frac{1}{\sigma^2} \operatorname{Trace} \left( \operatorname{Cov}(\hat{\mathbf{y}}, \mathbf{y}) \right)
\]
\[
\widehat{\mathbf{y}} = \mathbf{S} \mathbf{y}, \quad \text{其中} \quad \mathbf{S} = \mathbf{X}(\mathbf{X}^\top \mathbf{X} + \lambda \mathbf{I})^{-1} \mathbf{X}^\top
\]
\[
\text{df}(\lambda) = \operatorname{Trace}(\mathbf{S}) = \operatorname{Trace} \left( \mathbf{X}(\mathbf{X}^\top \mathbf{X} + \lambda \mathbf{I})^{-1} \mathbf{X}^\top \right)
\]
若对 \(\mathbf{X}\) ) :
\[
\mathbf{X} = UDV^\top, \quad \text{其中} \ D = \operatorname{diag}(d_1, \dots, d_p)
\]
\[
\boxed{
\text{df}(\lambda) = \sum_{j=1}^{p} \frac{d_j^2}{d_j^2 + \lambda}
}
\]
elastic
lasso 与 ridge
Ridge is \(\ell_{2}\) penalty
Lasso is \(\ell_{1}\) penalty
Best subset is \(\ell_{0}\) penalty
Bridge penalty is \(\ell_{q}\) normal
\(q = 4\) \(q = 2\) \(q = 1\) \(q = 0.5\) \(q = 0.1\)
\(\sum_{j}|\beta_{j}|^{q}\) for given values of \(q\) .
Elastic-net is a hybrid of \(\ell_{1}\) and \(\ell_{2}\) :
\(\lambda_{1}\|\beta\|_{1} + \lambda_{2}\|\beta\|_{2}^{2}\)
LDA
理解主成分分析(1)——最大方差投影与数据重建 - Fenrier Lab
简单理解线性判别分析 -
LDA 线性判别分析——投影的疑问解答 _lda -CSDN
最小化类内方差
\[
\begin{align*} &\quad \min\limits_w \left[\sum\limits_{x\in X_0}(w^Tx-w^T\mu_0)^2+\sum\limits_{x\in X_1}(w^Tx-w^T\mu_1)^2\right]\\ &=\min\limits_w w^T \left[\sum\limits_{x\in X_0}(x-\mu_0)(x-\mu_0)^T+\sum\limits_{x\in X_1}(x-\mu_1)(x-\mu_1)^T\right]w \\ &=\min\limits_w w^TS_ww \\ \end{align*}
\]
最大化类间方差
\[
\begin{align*} &\quad \max\limits_w \left[(w^T\mu_0-\frac{w^T\mu_0+w^T\mu_1}{2})^2+(w^T\mu_1-\frac{w^T\mu_0+w^T\mu_1}{2})^2\right]\\ &=\max\limits_w \frac{1}{2}w^T(\mu_0-\mu_1)(\mu_0-\mu_1)^Tw\\ &=\max\limits_w \frac{1}{2}w^TS_bw \\ \end{align*}
\]
因为自变量只有 \(w\)
\[
J = \displaystyle \frac{w^TS_bw}{w^TS_ww}
\]
LDA——线性判别分析基本推导与实验 -CSDN
二分类线性判别分析,看懂这篇就够了 -