重点问题讨论 ¶
约 665 个字 3 张图片 预计阅读时间 3 分钟
残差连接 ¶
- 残差连接:通过将输入信号直接添加到输出信号中,可以有效地解决梯度消失问题,提高模型的训练速度和性能。
Layer Norm¶
- GPT3:采用了 Post-Layer Normalization(后标准化)的结构,即先进行自注意力或前馈神经网络的计算,然后进行 Layer Normalization。这种结构有助于稳定训练过程,提高模型性能。
- LLAMA:采用了 Pre-Layer Normalization(前标准化)的结构,即先进行 Layer Normalization,然后进行自注意力或前馈神经网络的计算。这种结构有助于提高模型的泛化能力和鲁棒性。
- ChatGLM:采用了 Post-Layer Normalization 的结构,类似于 GPT3。这种结构可以提高模型的性能和稳定性。
激活函数 ¶
- ReLU(Rectified Linear Unit
) :一种简单的激活函数,可以解决梯度消失问题,加快训练速度。 - GeLU(Gaussian Error Linear Unit
) :一种改进的 ReLU 函数,可以提供更好的性能和泛化能力。 - Swish:一种自门控激活函数,可以提供非线性变换,并具有平滑和非单调的特性。
FFN - 大模型的事实藏在哪里 ¶
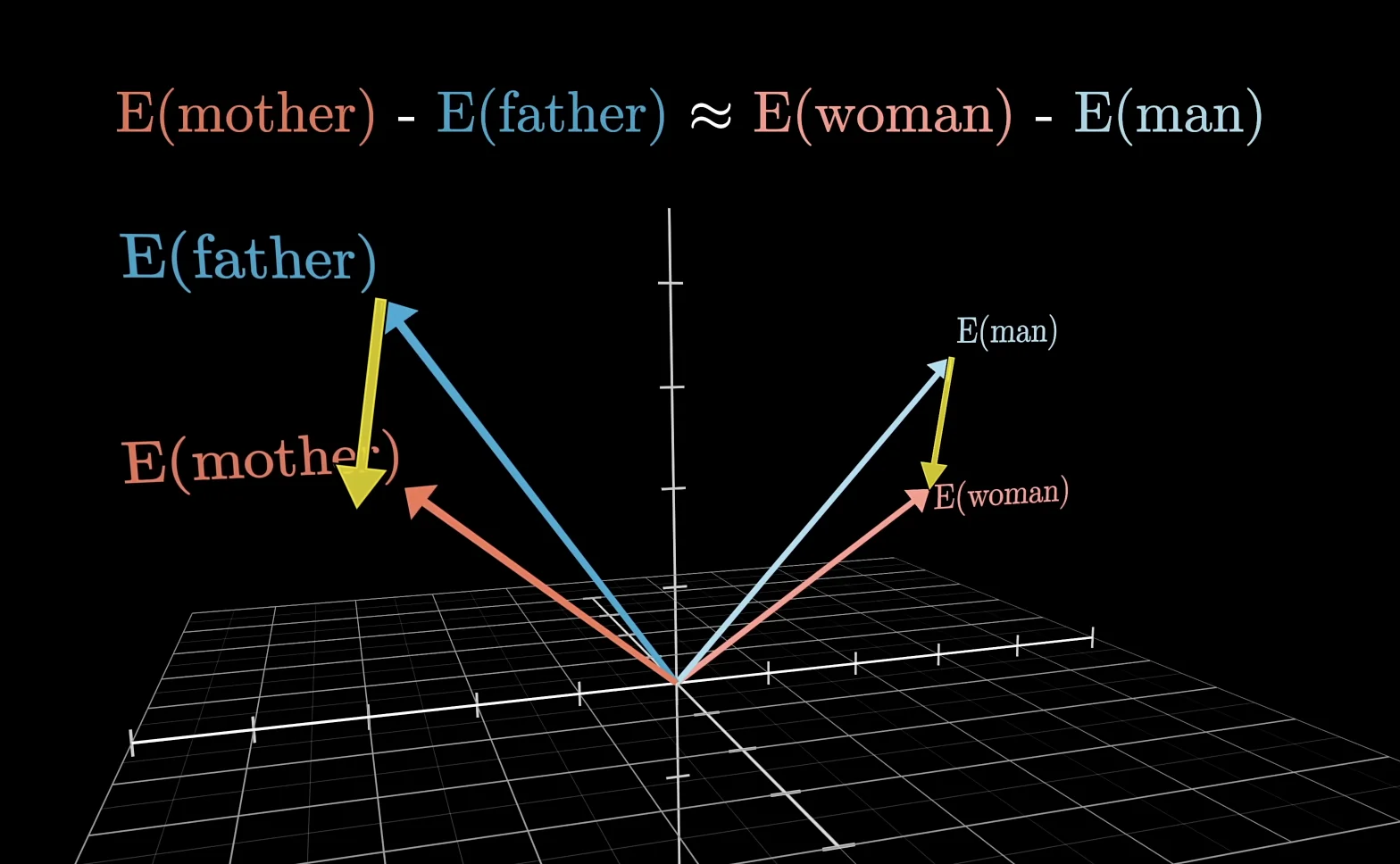
词汇存在高维向量当中,向量的方向可以编码不同的含义
transformer 大部分的参数在 MLP 层当中(约占用 \(\frac{2}{3}\) 的参数,GPT3 - 12 亿)
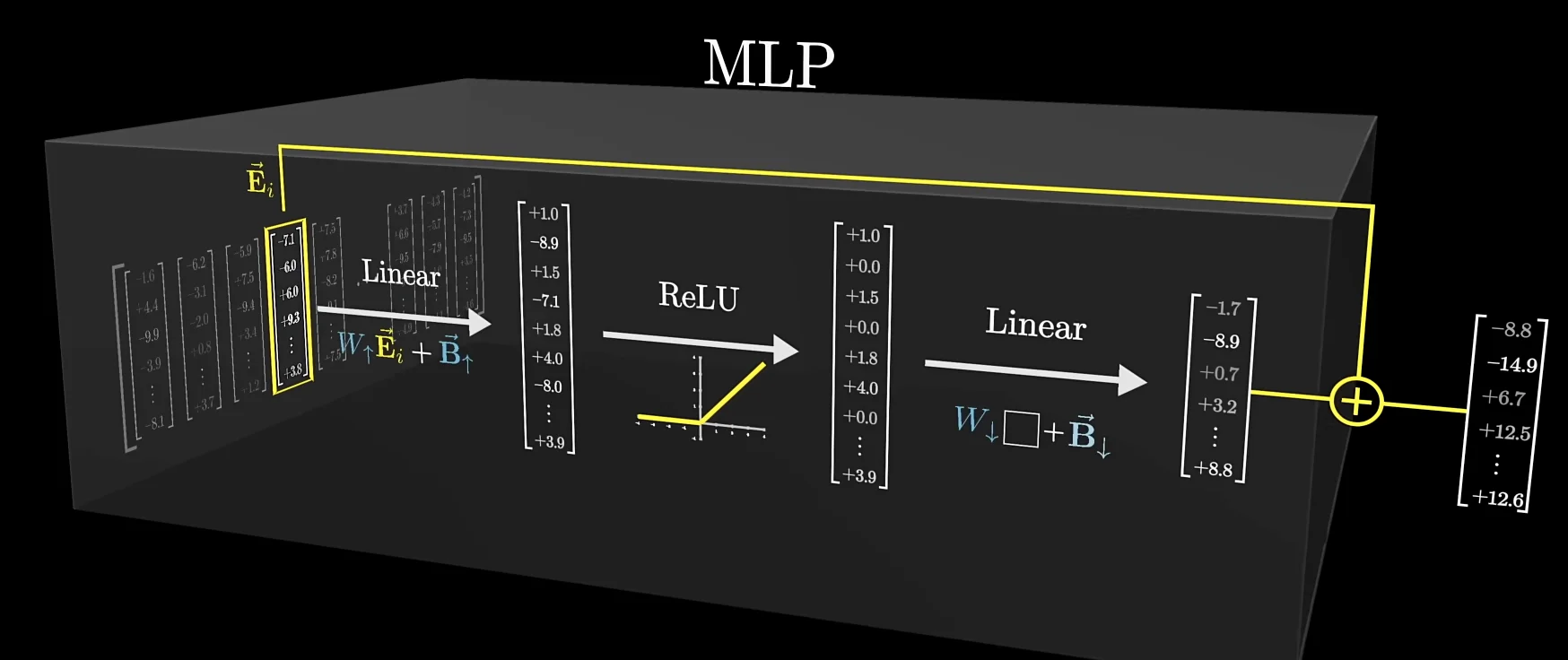
第一个线性层可以使用行视角,视作嵌入空间中的方向
ReLU 类似于与门,只有最终结果为正数时,才会输出
第二个线性层,可以使用列视角:如果某个列向量学习到了“篮球”的概念,同时对应的列向量 ( 如 \(n_0\)) 又被激活,那么最后的加权向量当中就可以表示“篮球”的概念

在 \(N\) 维空间当中,如果使用正交基表示一个概念,那么最多只能表示 \(N\) 个概念
johnson-lindenstrauss lemma 告诉我们,如果使用非正交基,那么可以表示更多的概念,尤其是在高维空间当中。能表示的概念数量与维数 \(n\) 成指数分布
这也说明,某个概念并不是单纯由一个单元激活,而是由多个单元激活(superposition)
拓展阅读 ¶
芝加哥大学 victor veitch 的论文
Anthropic Transformer circuit
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
- RLHF
- scaling law
消融实验 ¶
- 消融实验:通过逐步移除模型中的某些组件或参数,观察模型性能的变化,从而确定模型中哪些组件或参数对模型性能的提升最为重要。