04 | SFT¶
约 546 个字 108 行代码 2 张图片 预计阅读时间 3 分钟
llama-factory 使用记录 ¶
Llama-factory
Llama-factory 是一个用于大规模语言模型(LLM)训练和推理的框架。它提供了一套工具和接口,简化了从数据准备到模型部署的整个流程。Llama-factory 支持多种模型架构和数据集,允许用户根据自己的需求进行定制和扩展。通过集成的 WebUI,用户可以方便地管理模型训练过程,调整参数,并实时监控训练进度和性能指标。此外,Llama-factory 还支持分布式训练和推理,能够有效利用多台机器的计算资源,提高模型的训练效率和推理速度。
安装与使用 ¶
llama-factory SFT 系列教程 ( 二 ),大模型在自定义数据集 lora 训练与部署 _llama-factory 自定义数据集 -CSDN 博客
这里使用 AutoDL 上的社区镜像
实战记录 —— 微调 qwen 实现 Multi30K 下英译德翻译模型 ¶
使用的是 Multi30K 数据集,下载地址:https://github.com/neychev/small_DL_repo/tree/master/datasets/Multi30k
下载模型 ¶
下载Qwen2.5-7B-Instruct模型,放在/root/Qwen2.5-7B-Instruct下
准备数据 ¶
根据 sft 的格式,整理数据,按照 instruction, input, output 格式
{
"instruction": "Translate the following English text to German.",
"input": "Two young, White males are outside near many bushes.",
"output": "Zwei junge weiße Männer sind im Freien in der Nähe vieler Büsche."
}
开启 webui ¶
开启 webui 之后,操作比较简单,只需要选择对应的模型,修改参数,填写对应路径,即可进行训练
进行训练 ¶
- PEFT 0.12.0
- Transformers 4.45.2
- Pytorch 2.4.1+cu121
- Datasets 2.21.0
- Tokenizers 0.20.1
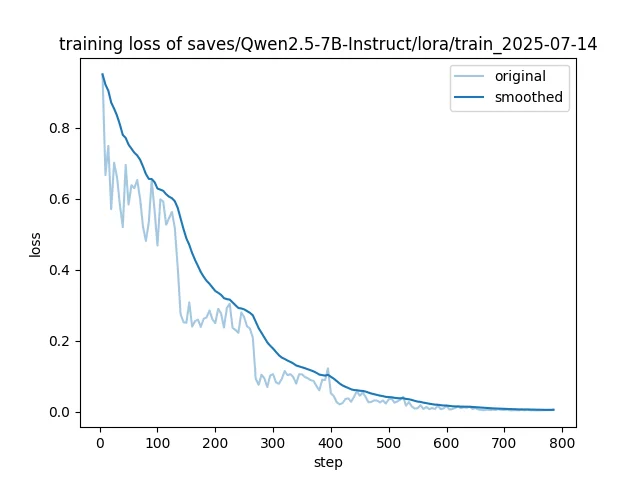
可以中途切断,loss 不需要太低
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /root/LLaMA-Factory/src/output/en2de \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen \
--flash_attn auto \
--dataset_dir /root/LLaMA-Factory/data \
--dataset 你的数据集 \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 6.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir saves/Qwen2.5-7B-Instruct/lora/train_2025-07-14-22-51-16 \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout 0 \
--loraplus_lr_ratio 16 \
--lora_target all
API 推理 ¶
在服务器上执行
source activate llama
cd /root/LLaMA-Factory
CUDA_VISIBLE_DEVICES=0 API_PORT=6006 python src/api.py \
--model_name_or_path /root/LLaMA-Factory/src/output/en2de \
--template qwen \
相当于把这项服务部署到了服务器的端口上,然后通过 openai 的 api 进行调用,就可以实现推理
import openai
import sys
api_key = "EMPTY"
openai.api_base = "http://localhost:6006/v1"
def chat_with_gpt3_5(messages):
response = openai.ChatCompletion.create(
model="xxx",
messages=messages,
api_key=api_key,
stream=True # 启用流式输出
)
full_response = ""
for chunk in response:
if 'choices' in chunk and len(chunk['choices']) > 0:
content = chunk['choices'][0].get('delta', {}).get('content', '')
if content:
print(content, end='', flush=True)
full_response += content
print()
return full_response
conversation = [
{"role": "system", "content": "你是一个聪明的 AI"}
]
while True:
user_input = input("You: ")
if user_input.lower() == '退出':
print("Assistant: 再见!")
break
conversation.append({"role": "user", "content": user_input})
print("Assistant: ", end='', flush=True)
assistant_message = chat_with_gpt3_5(conversation)
conversation.append({"role": "assistant", "content": assistant_message})
则可以在本地浏览器访问http://localhost:6006,进行推理,也可以通过 api 进行调用
下面的代码中我测试了英译德的测试集 1000 个样本,达到了 44.45 的 bleu 分数
Original English: 2 blond girls are sitting on a ledge in a crowded plaza.
Translation: 2 blonde Mädchen sitzen auf einer Fassade in einem überfüllten Platz.
Reference German: 2 blonde Mädchen sitzen auf einem Absatz auf einem belebten Platz.
BLEU score: 66.23282548391518
Original English: A child is splashing in the water
Translation: Ein Kind macht im Wasser Platsch.
Reference German: Ein Kind planscht im Wasser.
BLEU score: 66.64762996818769
Original English: Three people sit at a picnic table outside of a building painted like a union jack.
Translation: Drei Personen sitzen an einem Picknicktisch vor einem Gebäude, das wie ein Union Jack gemalt ist.
Reference German: Drei Leute sitzen an einem Picknicktisch vor einem Gebäude, das wie der Union Jack bemalt ist.
BLEU score: 85.15116314550686
Translation English to German and calculating BLEU scores...
100%|█████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [09:52<00:00, 1.69it/s]
Average BLEU score for DE to EN: 44.44732087434253
问题解决 ¶
-
模型问题,下载模型
-
如果下载出现问题,会报错
safetensors_rust.SafetensorError: Error while deserializing header: MetadataIncompleteBuffer
-
-
模版问题:使用
llama3模版:可以在template.py中添加自己的对话模板。 - lora 问题
ValueError: Target modules {'c_attn'} not found in the base model. Please check the target modules and try again.改成
q_proj,v_proj--lora_target q_proj,v_proj