03 | 训练方法 ¶
约 1043 个字 9 行代码 1 张图片 预计阅读时间 4 分钟
随机梯度下降:随机采样
关注的不是收敛快不快,而是收敛到哪一个点;牛顿法可能不平坦
训练过程 ¶
对于每一个小批量,我们会进行以下步骤 :
- 通过调用 net(X) 生成预测并计算损失 l(前向传播
) 。 - 通过进行反向传播来计算梯度。
- 通过调用优化器来更新模型参数。
训练框架 ¶
epoch: 训练轮次
iter 训练小批量
nn 模块定义了大量的神经网络层和常见损失函数。
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)
trainer.zero_grad() # 清除梯度,防止累计
l.backward() # 自动计算梯度
trainer.step() # 优化算法
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')
初始化 ¶
可以使用固定的初始值,但是不能为 0
如果我们将权重初始化为零,会发生什么。算法仍然有效吗?
如果将权重初始化为零,那么每个神经元的输出都是相同的,这意味着每个神经元学习到的参数也是相同的。因此,每个神经元都会更新相同的参数,最终导致所有神经元学习到相同的特征。因此,权重初始化为零会使算法失效。这样就失去了神经网络的优势,即可以学习到不同特征的能力。
逻辑回归和神经网络有不同的权重初始化方法。对于逻辑回归,可以将权重初始化为零,因为这是一个线性模型,梯度下降算法仍然可以更新它们。然而,对于神经网络来说,将权重初始化为零可能会导致对称性问题,并阻止隐藏单元学习不同的特征。因此,最好使用随机或其他方法来初始化神经网络的权重。
学习率 ¶
尝试使用不同的学习率,观察损失函数值下降的快慢。
学习率过大前期损失值下降快,但是后面不容易收敛 学习率太小,损失函数下降慢
调学习率的一些心得 1. 选择对学习率不太敏感的算法:Adam 2. 合理的参数的初始化
学习率设置过大会导致梯度爆炸的问题
收敛判断 | epoch ¶
- 真实训练中,凭直觉
- 先训练小批次
损失函数 | 统计模型 ¶
如果将小批量的总损失替换为小批量损失的平均值,需要如何更改学习率?
如果将小批量的总损失替换为小批量损失的平均值,则需要将学习率乘以批量大小。这是因为在计算梯度时,我们使用了小批量中所有样本的信息。因此,如果我们将小批量的总损失替换为小批量损失的平均值,则相当于将每个样本的梯度除以批量大小。因此,我们需要将学习率乘以批量大小,以保持相同的更新步长
损失为什么求平均:更好调学习率,相当于学习率之和梯度有关,和 batch size 没有关系
每次算梯度的时候要记得清零,不然会做累加
l1 loss¶
不常用绝对差值而用平方损失:不好求导
有不平滑性,可能不稳定
离远点较远的时候,不一定希望有一个很大的梯度
l2 loss¶
Huber Robust loss¶
softmax 回归 ¶
- 不仅对硬分类感兴趣,还对软分类(概率)感兴趣
直接使用实数对应不太合适,所以使用向量来代表分类
为什么使用 ¶
- 线性有可能有负数,概率应该是非负的
- 概率之和需要为 1
交叉熵 ¶
信息论:
信息量 : 不确定 -》确定的难度
可以理解为惊异程度,不确定度更大,则信息量更大
系统的熵
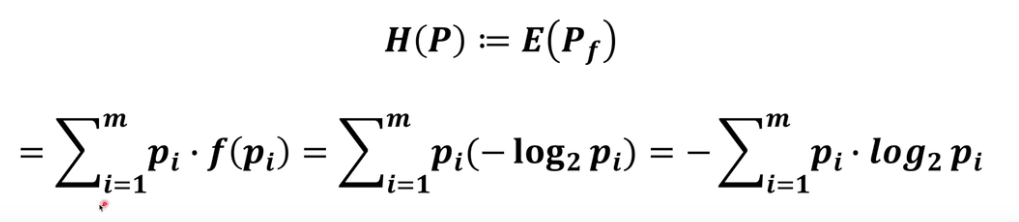
KL 散度
交叉熵
衡量两个概率的区别
我们可以把交叉熵想象为“主观概率为 \(Q\) 的观察者在看到根据概率 \(P\) 生成的数据时的预期惊异”。
(i)最大化观测数据的似然; (ii)最小化传达标签所需的惊异。